提高FlexSPI接口与FPGA接口通信速度方法
前言
之前的项目中使用RT1052的FlexSPI X8 接口与FPGA通信成功,但是100MHz的SCLK时钟频率,通信速度只达到了9MB/S左右,通信效率不高。最近有项目需要高速通信,重新翻出以前的代码进行优化,成功让FlexSPI接口与FPGA通信速度达到76.9MB/S(理论上还可以更高,待继续优化)。
分析
通过分析,一方面是串行接口需要传输指令、地址、数据长度等信息,如果一次传输4字节(传输长度受AHB总线和是否启用Cache等因素影响),这几个信息就占用了超过一半的带宽资源(见如下LUT表指令 Read Data 描述),另一方面没有启用缓存和Dcache功能,没有发挥iMXRT芯片的实力。

LUT表如下
static const uint32_t customLUT[CUSTOM_LUT_LENGTH] = {/* Read Data */[4 * FPGARAM_CMD_LUT_SEQ_IDX_READDATA] =FLEXSPI_LUT_SEQ(kFLEXSPI_Command_SDR, kFLEXSPI_8PAD, 0xA0, kFLEXSPI_Command_RADDR_SDR, kFLEXSPI_8PAD, 0x18),// 指令 0xA0,地址长度0x18 = 24位[4 * FPGARAM_CMD_LUT_SEQ_IDX_READDATA + 1] =FLEXSPI_LUT_SEQ(kFLEXSPI_Command_DATSZ_SDR, kFLEXSPI_8PAD, 0x08, kFLEXSPI_Command_DUMMY_SDR, kFLEXSPI_8PAD, 0x01), // DATSZ_SDR 可用于通知外部设备有多少个时钟周期 添加一个kFLEXSPI_Command_DUMMY_SDR 周期用于等待DQS切换方向[4 * FPGARAM_CMD_LUT_SEQ_IDX_READDATA + 2] =FLEXSPI_LUT_SEQ(kFLEXSPI_Command_READ_SDR, kFLEXSPI_8PAD, 0x04, kFLEXSPI_Command_STOP, kFLEXSPI_8PAD, 0x00),/* Write Data */[4 * FPGARAM_CMD_LUT_SEQ_IDX_WRITEDATA] =FLEXSPI_LUT_SEQ(kFLEXSPI_Command_SDR, kFLEXSPI_8PAD, 0x20, kFLEXSPI_Command_RADDR_SDR, kFLEXSPI_8PAD, 0x18),[4 * FPGARAM_CMD_LUT_SEQ_IDX_WRITEDATA + 1] = FLEXSPI_LUT_SEQ(kFLEXSPI_Command_DATSZ_SDR, kFLEXSPI_8PAD, 0x08, kFLEXSPI_Command_DUMMY_SDR, kFLEXSPI_8PAD, 0x01),[4 * FPGARAM_CMD_LUT_SEQ_IDX_WRITEDATA + 2] = FLEXSPI_LUT_SEQ(kFLEXSPI_Command_WRITE_SDR, kFLEXSPI_8PAD, 0x04, kFLEXSPI_Command_STOP, kFLEXSPI_8PAD, 0x00),
};FPGA设备访问描述配置如下
static flexspi_device_config_t deviceconfig = {.flexspiRootClk = 120000000, //此处赋值只是用于库函数FLEXSPI_SetFlashConfig 把它作为时间基准进行运算的.isSck2Enabled = false,.flashSize = M_FLASH_SIZE,.CSIntervalUnit = kFLEXSPI_CsIntervalUnit1SckCycle,.CSInterval = 0, //CS的最小 宽度.CSHoldTime = 1, //SCK最后一个时钟沿到CS上升沿的延迟.CSSetupTime = 0, //CS下降沿到 SCK上升沿时钟.dataValidTime = 1, //单位是0.1nS // 速度低于100M时才有效.columnspace = 0, //列地址宽度.enableWordAddress = true,.AWRSeqIndex = FPGARAM_CMD_LUT_SEQ_IDX_WRITEDATA,.AWRSeqNumber = 1,.ARDSeqIndex = FPGARAM_CMD_LUT_SEQ_IDX_READDATA,.ARDSeqNumber = 1,.AHBWriteWaitUnit = kFLEXSPI_AhbWriteWaitUnit2AhbCycle,.AHBWriteWaitInterval = 0, //0AHB时钟延迟.enableWriteMask = false, //写外部器件时DQS信号输出
};
解决思路
NXP官方有一个文档《AN12239 如何在 i.MX RT 上使用 HyperRAM》
https://download.csdn.net/download/catshit322/87580645
描述了提高FlexSPI访问速度的方法:
提高时钟速度
将数据放在DTCM,将代码放在ITCM中
启用预读取和写入缓冲
开启Dcache
受代码体积影响,我将代码全部放在SDRAM中运行,由FPGA独占FlexSPI接口访问带宽
实现
代码运行在SDRAM中
我的应用是将代码放在SPI Flash中存储,通过修改分散加载文件和拷贝中断向量表的方式,启动后将代码搬移到SDRAM中,再重新配置FlexSPI接口,然后通过AHB方式开始访问FPGA,FPGA通过FIFO的方式将数据进行输出,由于我的应用中通过地址区分需要发送的数据,因此地址字段(下图中0x30,0x0C,0x50)不能省去,只用到地址的最高4位,后面的数据用来实现FIFO连续输出。数据长度字段(0x20)用于通知FPGA输出多少个数据。如果不开启Cache功能,每次只能传输4字节(uint32_t)或8字节(uint64_t),下图是开启了缓冲功能后的时序图,每次可以传输32字节(与AHB RX buffer 缓冲区设置大小有关)。

初始化接口
使用的FlexSPI初始化函数如下:
void flexspi_init(void)
{flexspi_config_t config;flexspi_gpio_init();SCB_DisableDCache();/* Wait for bus to be idle before changing flash configuration. */while (false == FLEXSPI_GetBusIdleStatus(EXAMPLE_FLEXSPI)){}const clock_usb_pll_config_t g_ccmConfigUsbPll = {.loopDivider = 0U};FLEXSPI_Deinit(EXAMPLE_FLEXSPI);//初始化USB1PLL,即PLL3,loopDivider=0//所以USB1PLL=PLL3 = 24*20 = 480MHzCLOCK_InitUsb1Pll(&g_ccmConfigUsbPll); //Set PLL3 PFD0 clock: PLL3*18/24 = 360MHZCLOCK_InitUsb1Pfd(kCLOCK_Pfd0, 24); //选择PLL3 PFD0作为flexspi时钟源//00b derive clock from semc_clk_root_pre//01b derive clock from pll3_sw_clk//10b derive clock from PLL2 PFD2//11b derive clock from PLL3 PFD0 CLOCK_SetMux(kCLOCK_FlexspiMux, 0x03);//设置flexspiDiv分频因子,得到FLEXSPI_CLK_ROOT = PLL3 PFD0/(flexspiDiv+1) = 120M.uint8_t div = 2;CLOCK_SetDiv(kCLOCK_FlexspiDiv, div);uint32_t coreclk = CLOCK_GetFreq(kCLOCK_CpuClk);uint32_t ahbclk = CLOCK_GetFreq(kCLOCK_AhbClk);uint32_t fpgabusclk = CLOCK_GetFreq(kCLOCK_Usb1PllPfd0Clk)/(div+1);printf("coreclk:%d ahbclk:%d fpgabusclk:%d\r\n", coreclk, ahbclk, fpgabusclk);FLEXSPI_GetDefaultConfig(&config); //Get FLEXSPI default settings and configure the flexspi.config.rxSampleClock = kFLEXSPI_ReadSampleClkExternalInputFromDqsPad; // 使用外部回环 最高 166M SDR
// config.rxSampleClock = kFLEXSPI_ReadSampleClkLoopbackInternally; // 使用内部回环 最高 60M SDR
// config.rxSampleClock = kFLEXSPI_ReadSampleClkLoopbackFromSckPad ; //使用自SCK信号 最高133M SDR
// config.rxSampleClock = kFLEXSPI_ReadSampleClkLoopbackFromDqsPad ; //使用自回环 最高133M SDRconfig.enableSckFreeRunning = true; ///持续运行为FPGA提供时钟config.ahbConfig.enableReadAddressOpt = false; /// 使用FPGA fifo时应为false ,否则出现地址对齐问题同一地址多次读取FPGA无法识别config.enableCombination = true; // 使用8位模式
// config.txWatermark = 8; // AHB 模式下无用
// config.rxWatermark = 8;config.ahbConfig.enableAHBPrefetch = false; //AHB 预读取功能,开启此功能后 数据长度指令无效,无法传输准确的读取长度给FPGA,由CS引脚控制config.ahbConfig.enableAHBBufferable = true;config.ahbConfig.enableAHBCachable = true;/*Set AHB buffer size for reading data through AHB bus. */// 配置4个 AHB RX BUFFERfor(char i = 0;i < FSL_FEATURE_FLEXSPI_AHB_BUFFER_COUNT ; i++ ){
// config.ahbConfig.buffer[i].priority = 1; config.ahbConfig.buffer[i].masterIndex = i; config.ahbConfig.buffer[i].bufferSize = 256;}FLEXSPI_Init(EXAMPLE_FLEXSPI, &config);deviceconfig.flashSize = 0x4000; /// A1 寻址范围0x6000000 0x60FFFFFF 0x1000000 = 0x4000 * 1024FLEXSPI_SetFlashConfig(EXAMPLE_FLEXSPI, &deviceconfig, kFLEXSPI_PortA1);//A2 寻址范围 0x6100 0000 ~ 0x6184 0000+/* Set flexspi root clock. */deviceconfig.flexspiRootClk = flexspi_get_frequency();FLEXSPI_SetFlashConfig(EXAMPLE_FLEXSPI, &deviceconfig, kFLEXSPI_PortA2);//Configure flash settings according to serial flash feature.FLEXSPI_UpdateLUT(EXAMPLE_FLEXSPI, 0, customLUT, CUSTOM_LUT_LENGTH); //Update LUT table/* Do software reset. */FLEXSPI_SoftwareReset(EXAMPLE_FLEXSPI);SCB_EnableDCache();
}打开缓存功能
需要注意的是开始启Cache功能会导致FlexSPI接口不按预期去读取外部数据,使用时需要特别处理,有两种方法。
第一种方法
设置MPU,将FPGA映射的地址设置为Non-Cacheable。
/* Memory with Normal type, not shareable, non-cacheable */MPU->RBAR = ARM_MPU_RBAR(10, 0x61000000U);MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 1, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_256MB);/// cacheable
// MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 0, 0, 1, 1, 0, ARM_MPU_REGION_SIZE_256MB);此时
config.ahbConfig.enableAHBBufferable = true;
config.ahbConfig.enableAHBCachable = true;
选项实际不起作用,测试的读取速度如下图(时间精度为100us)
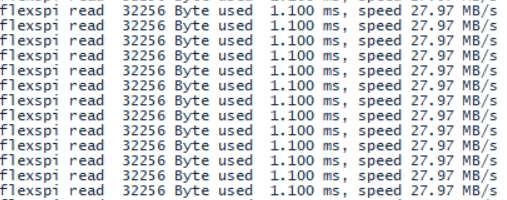
经过测试读取速度可以达到27.97MB/S,与理论速度仍有较大差距。
第二种方法
另一种方法是将FPGA映射的地址设置为Cacheable,开启缓存功能。
/* Memory with Normal type, not shareable, non-cacheable */MPU->RBAR = ARM_MPU_RBAR(10, 0x61000000U);
// MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 1, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_256MB);/// cacheableMPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 0, 0, 1, 1, 0, ARM_MPU_REGION_SIZE_256MB);在读取FPGA之前先使用无效化缓存指令使内部缓存无效,强制去读取外部设备以产生访问时序。
DCACHE_InvalidateByRange((EXAMPLE_FLEXSPI_AMBA_BASE + addr), len);
DCACHE_CleanByRange((EXAMPLE_FLEXSPI_AMBA_BASE + addr), len);然后使用AHB方式访问FPGA
flexspi_ahbcommand_read_data(addr, Psave_buf, len); // 读数据flexspi_ahbcommand_read_data 实现代码为
void flexspi_ahbcommand_read_data(uint32_t address, uint8_t *buffer, uint32_t length)
{uint64_t* startAddr = (uint64_t*)(EXAMPLE_FLEXSPI_AMBA_BASE + address);uint64_t * Pbuf = (uint64_t*) buffer;uint32_t len = length/sizeof(uint64_t);for(int i = 0;i实测通信速度如下图:
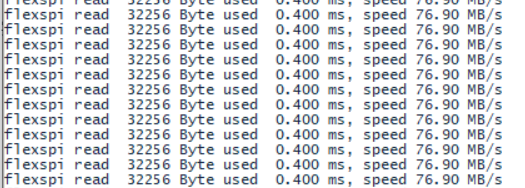
虽然与理论最大速度仍有差距,但是现阶段已经满足使用要求,待接下来有时间再继续优化。
总结
根据《AN12239 如何在 i.MX RT 上使用 HyperRAM》文档对RT1052程序进行优化,现在可以达到76.9MB/S的读取速度,受FPGA逻辑影响,无法开启所有优化方式,下一步有时间再研究如何让RT1052和FPGA通信达到官方测试的最高281MB/S的读取速度。