每日学术速递3.16
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
1.One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale

标题:一个适合大规模多模态扩散中的所有分布的Transformer
作者:Fan Bao, Shen Nie, Kaiwen Xue, Chongxuan Li, Shi Pu, Yaole Wang
文章链接:https://arxiv.org/abs/2303.06555
项目代码:https://github.com/thu-ml/unidiffuser

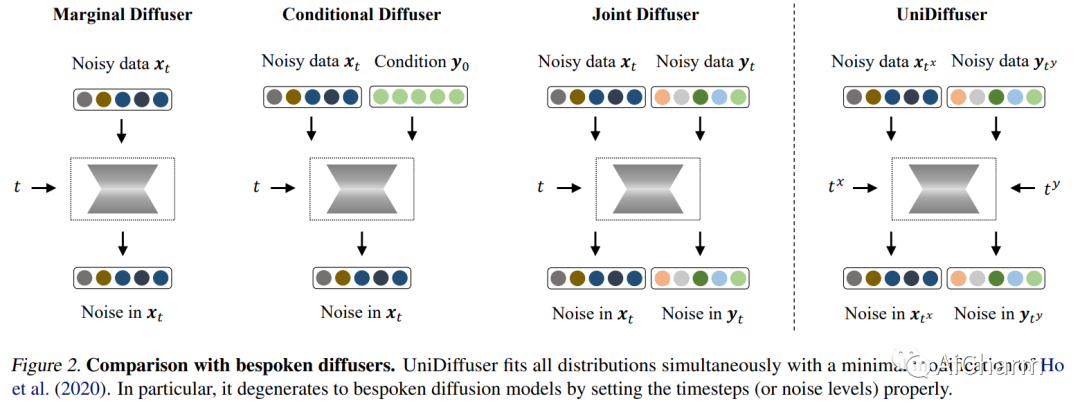
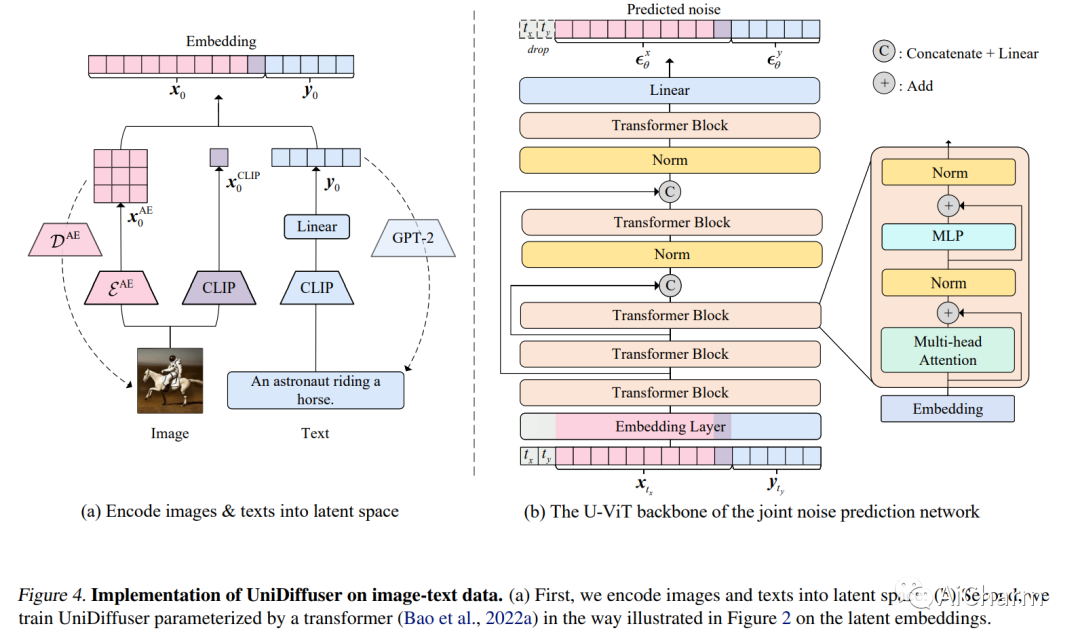
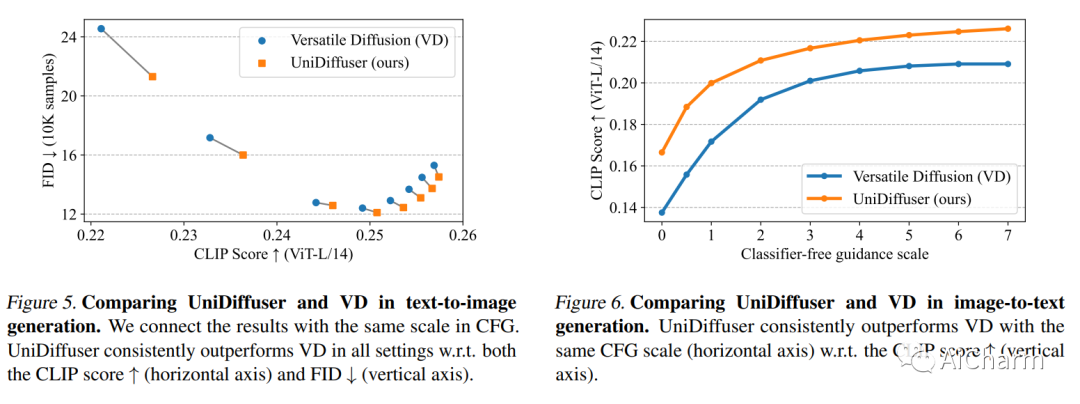
摘要:
本文提出了一个统一的扩散框架(称为 UniDiffuser),以在一个模型中拟合与一组多模态数据相关的所有分布。我们的关键见解是——学习边缘分布、条件分布和联合分布的扩散模型可以统一为预测扰动数据中的噪声,其中扰动水平(即时间步长)对于不同的模式可能不同。受统一视图的启发,UniDiffuser 通过对原始扩散模型进行最小修改同时学习所有分布——扰乱所有模态而不是单一模态的数据,在不同模态中输入单独的时间步长,并预测所有模态的噪声而不是单一模态单一模式。UniDiffuser 由扩散模型的转换器参数化,以处理不同模式的输入类型。UniDiffuser 在大规模成对图像文本数据上实现,能够通过设置适当的时间步来执行图像、文本、文本到图像、图像到文本和图像文本对生成,而无需额外的开销。特别是,UniDiffuser 能够在所有任务中产生感知真实的样本,其定量结果(例如,FID 和 CLIP 分数)不仅优于现有的通用模型,而且与定制模型(例如,Stable Diffusion 和DALL-E 2) 在代表性任务中(例如,文本到图像生成)。
2.Tag2Text: Guiding Vision-Language Model via Image Tagging

标题:Tag2Text:通过图像标记引导视觉语言模型
作者:Xinyu Huang, Youcai Zhang, Jinyu Ma, Weiwei Tian, Rui Feng, Yuejie Zhang, Yaqian Li, Yandong Guo, Lei Zhang
文章链接:https://arxiv.org/abs/2302.01791v1
项目代码:https://github.com/jiaojiayuasd/dilateformer

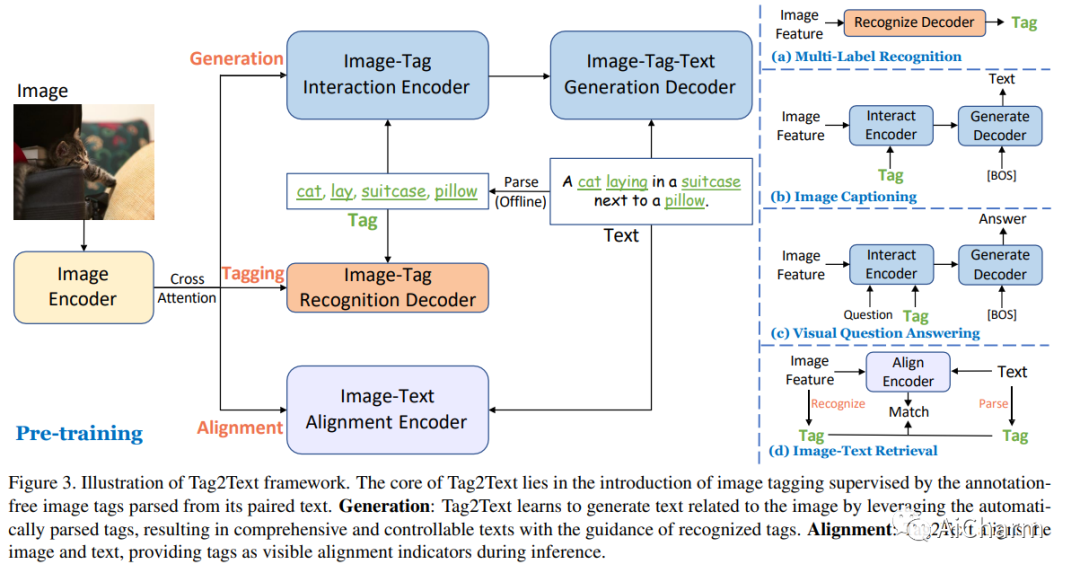
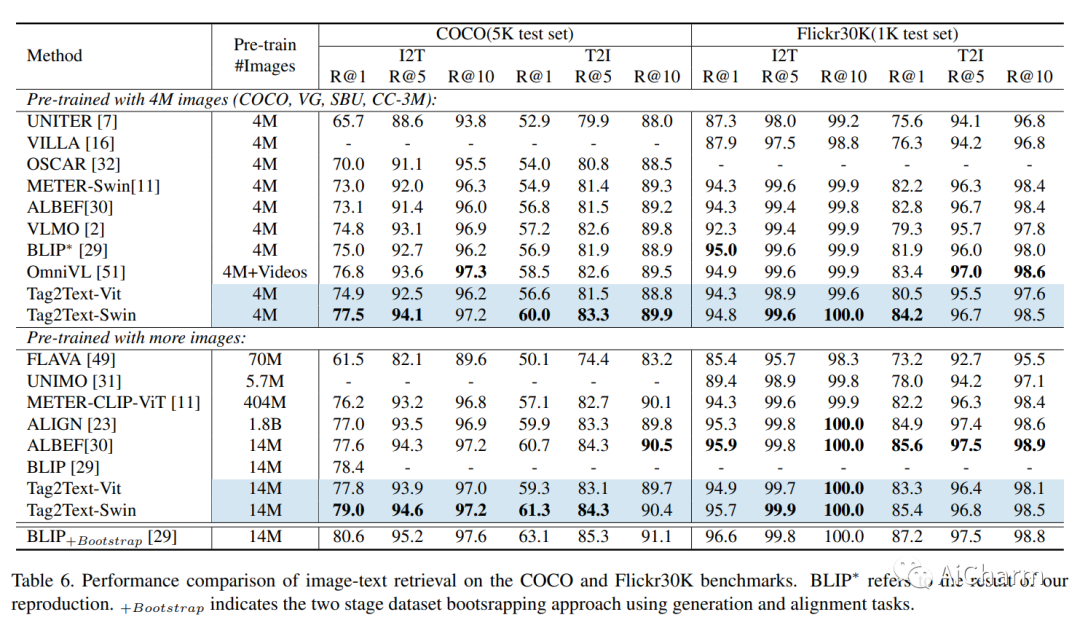
摘要:
本文介绍了 Tag2Text,一种视觉语言预训练 (VLP) 框架,它将图像标记引入视觉语言模型以指导视觉语言特征的学习。与使用手动标记或使用有限检测器自动检测的对象标签的先前工作相比,我们的方法利用从其配对文本解析的标签来学习图像标记器,同时为视觉语言模型提供指导。鉴于此,Tag2Text 可以根据图像文本对使用大规模无注释图像标签,并提供超越对象的更多样化的标签类别。因此,Tag2Text 通过利用细粒度的文本信息实现了卓越的图像标签识别能力。此外,通过利用标记指导,Tag2Text 有效地增强了视觉语言模型在基于生成和基于对齐的任务上的性能。在广泛的下游基准测试中,Tag2Text 以相似的模型大小和数据规模取得了最先进或有竞争力的结果,证明了所提出的标记指南的有效性。
3.Unifying Vision, Text, and Layout for Universal Document Processing
标题:为通用文档处理统一视觉、文本和布局
作者:Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal
文章链接:https://arxiv.org/abs/2302.01660v2
项目代码:https://github.com/ysig/learnable-typewriter
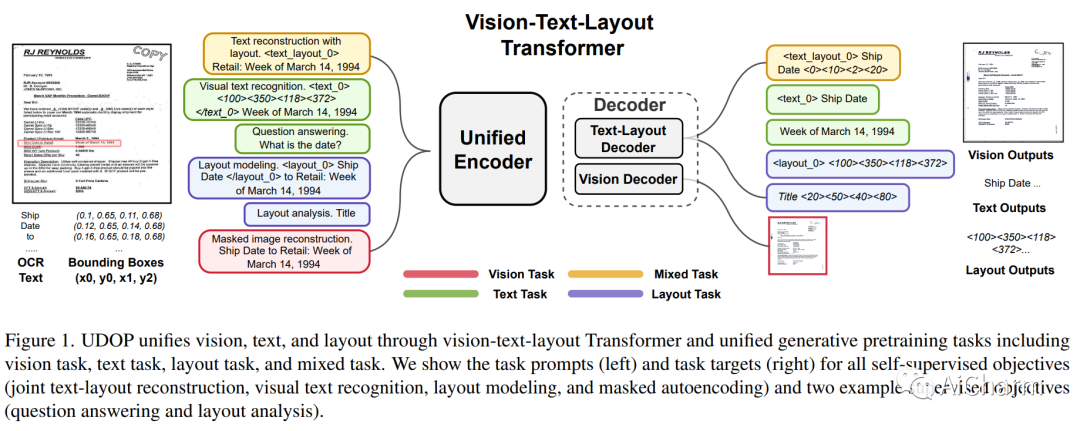
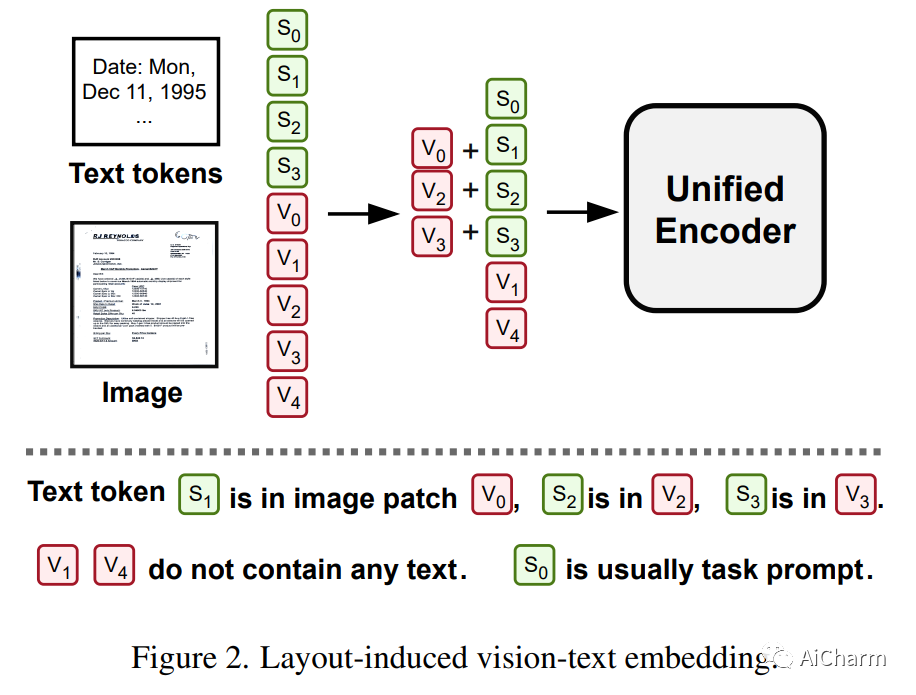
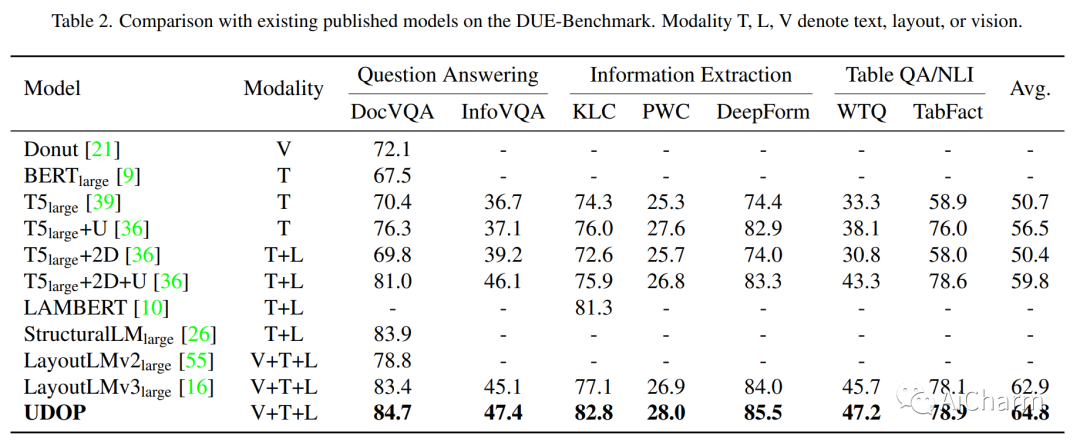
摘要:
我们提出了通用文档处理 (UDOP),这是一个基础文档 AI 模型,它统一了文本、图像和布局模式以及各种任务格式,包括文档理解和生成。UDOP 利用文本内容和文档图像之间的空间相关性,以一种统一的表示形式对图像、文本和布局模态进行建模。借助新颖的 Vision-Text-Layout Transformer,UDOP 将预训练和多域下游任务统一到基于提示的序列生成方案中。UDOP 使用创新的自我监督目标和多样化的标记数据在大规模未标记文档语料库上进行了预训练。UDOP 还学习通过蒙版图像重建从文本和布局模态生成文档图像。据我们所知,这是文档 AI 领域中第一次一个模型同时实现高质量的神经文档编辑和内容定制。我们的方法在财务报告、学术论文和网站等不同数据领域的 8 项文档 AI 任务(例如文档理解和 QA)上设置了最先进的技术。UDOP 在 Document Understanding Benchmark 的排行榜上名列第一。
更多Ai资讯:公主号AiCharm