pandas数据分析(三)
创始人
2025-05-29 03:01:14
0次
书接pandas数据分析(二)
文章目录
- DataFrame数据处理与分析
- 处理超市交易数据中的异常值
- 处理超市交易数据中的缺失值
- 处理超市交易数据中的重复值
- 使用数据差分查看员工业绩波动情况
- 使用透视表与交叉表查看业绩汇总数据
- 使用重采样技术按时间段查看员工业绩
DataFrame数据处理与分析
处理超市交易数据中的异常值
导入数据
import pandas as pd
# 设置列对齐
pd.set_option('display.unicode.ambiguous_as_wide',True)
pd.set_option('display.unicode.east_asian_width',True)
# 读取全部数据,使用默认索引
df=pd.read_excel('./超市营业额2.xlsx')
df[df.交易额<200]#交易额低于200的数据
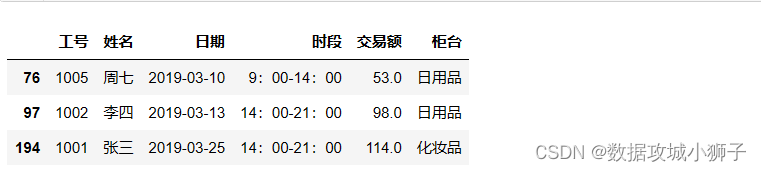
# 上浮50%之后仍低于200的数据
df.loc[df.交易额<200,'交易额']=df[df.交易额<200]['交易额'].map(lambda num:num*1.5)
df[df.交易额<200]
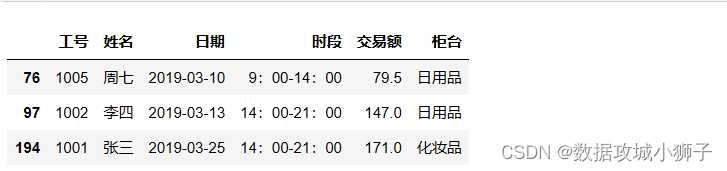
# 交易额高于3000的数据
df[df['交易额']>3000]

# 交易额低于200或高于3000的数据
df[(df.交易额<200)|(df.交易额>3000)]
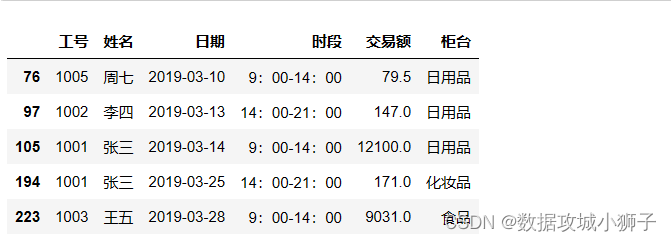
# 低于200的交易额替换为固定的200
df.loc[df.交易额<200,'交易额']=200
# 高于3000的交易额替换为固定的3000
df.loc[df.交易额>3000,'交易额']=3000
# 交易额低于200或高于3000的数据
df[(df.交易额<200)|(df.交易额>3000)]

处理超市交易数据中的缺失值
DataFrame结构支持dropna()方法丢弃带有缺失值的数据行,或者使用fillna()方法对缺失值进行批量替换。
dropna(axis=0,how='any',thresh=None,subset=None,inplace=False)
- how=any表示只要某行包含缺失值就丢弃;all表示某行全部为缺失值才丢弃。
- thresh:用来指定保留包含几个非缺失值数据的行。
- subset:用来指定在判断缺失值时只考虑哪些列。
fillna(value=None,method=None,axis=None,inplace=False,limit=None,downcast=None,**kwargs)
- value:用来指定要替换的值
- method:用来指定填充缺失值的方式。pad/ffill使用扫描过程中遇到的最后一个有效值一直填充到下一个有效值。backfill/bfill使用缺失值之后遇到的第一个有效值填充前面遇到的所有连续缺失值。
- limit:用来指定设置了参数method时最多填充多少个连续的缺失值。
- inplace:True原地替换,修改原数据;False返回一个新的DataFrame,不修改原数据。
len(df)#数据总行数

len(df.dropna())#丢弃缺失值后的行数

df[df['交易额'].isnull()]#包含缺失值的行
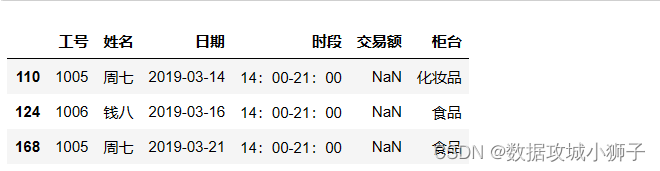
#使用固定值替换缺失值
from copy import deepcopy
dff=deepcopy(df)#深复制,不影响原来的df
dff.loc[dff.交易额.isnull(),'交易额']=1000
print(dff.iloc[[110,124,168],:])

#使用每人交易额均值替换缺失值
dff=deepcopy(df)
for i in dff[dff.交易额.isnull()].index:dff.loc[i,'交易额']=round(dff.loc[dff.姓名==dff.loc[i,'姓名'],'交易额'].mean())
print(dff.iloc[[110,124,168],:])

#使用整体均值的80%替换缺失值
df.fillna({'交易额':round(df['交易额'].mean()*0.8)},inplace=True)#替换原数据
print(df.iloc[[110,124,168],:])

处理超市交易数据中的重复值
len(df)#数据总行数

df[df.duplicated()]#重复行
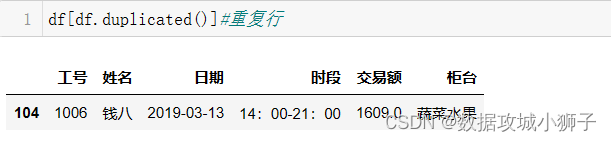
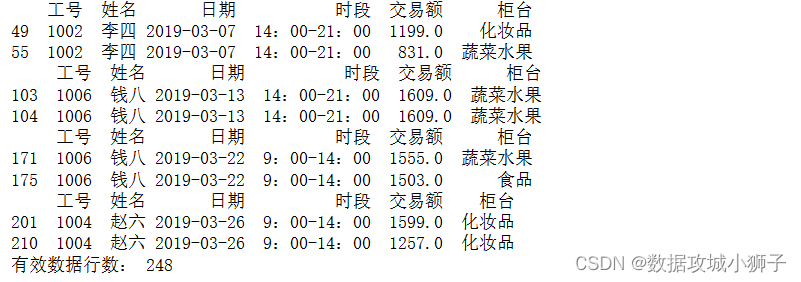
# 一人同时负责多个柜台的排班
dff=df[['工号','姓名','日期','时段']]
dff=dff[dff.duplicated()]
for row in dff.values:print(df[(df.工号==row[0])&(df.日期==row[2])&(df.时段==row[3])])
df=df.drop_duplicates()#直接丢弃重复行
print('有效数据行数:',len(df))
#查看是否有录入错误的工号和姓名
dff=df[['工号','姓名']]
print(dff.drop_duplicates())

使用数据差分查看员工业绩波动情况
数据差分diff(periods=1,axis=0)
periods=1且axis=0表示每一行数据减去紧邻的上一行数据
periods=2且axis=0表示每一行数据减去此行上面第二行数据
axis=0表示按行进行纵向差分,axis=1表示按列进行横向差分
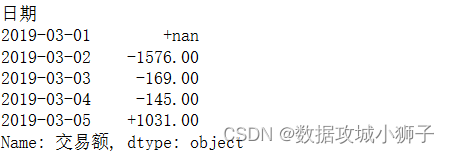
#每天交易额变化情况
dff=df.groupby(by='日期').sum()['交易额'].diff()
#格式化,正数前面带加号
print(dff.map(lambda num:'%+.2f'%num)[:5])

#张三每天交易总额变化情况
dff=df[df.姓名=='张三'].groupby(by='日期').sum()['交易额'].diff()
print(dff.map(lambda num:'%+.2f'%num)[:5])
使用透视表与交叉表查看业绩汇总数据
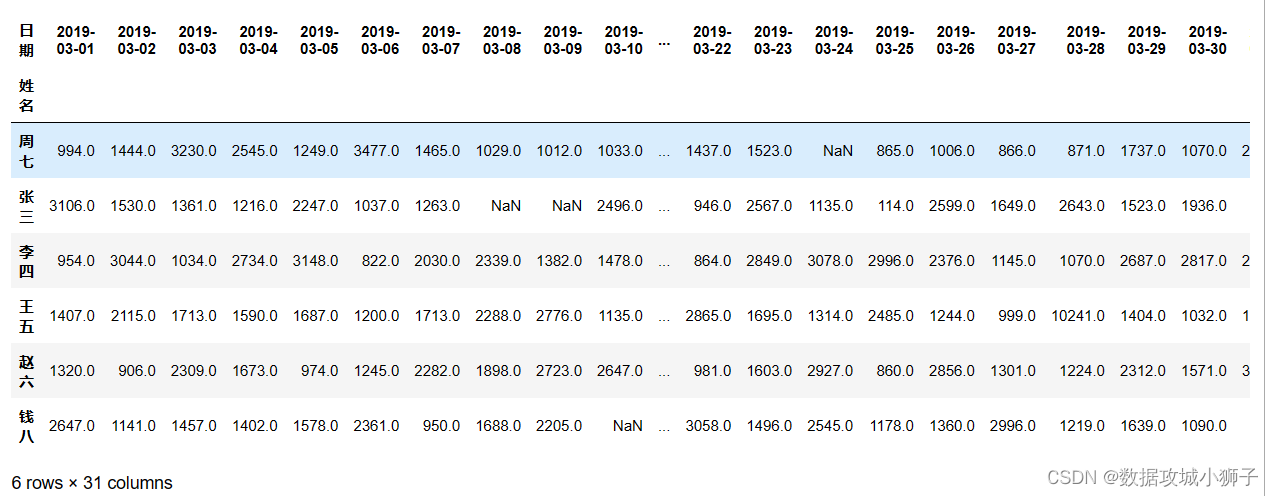
#每人每天交易总额
dff=df.groupby(by=['姓名','日期'],as_index=False).sum()
dff=dff.pivot(index='姓名',columns='日期',values='交易额')
dff
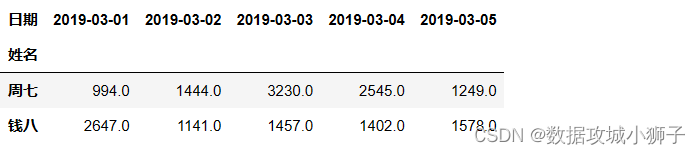
#交易总额低于5万元的员工前5天业绩
dff[dff.sum(axis=1)<50000].iloc[:,:5]
#交易总额低于5万元的员工姓名
print(dff[dff.sum(axis=1)<50000].index.values)
['周七' '钱八']
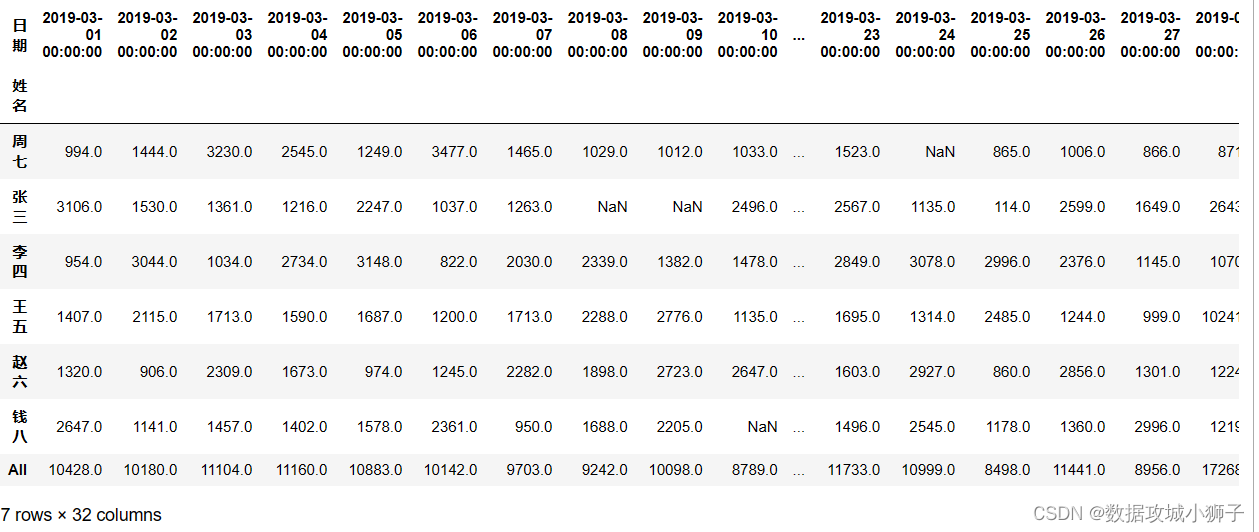
df.pivot_table(values='交易额',index='姓名',columns='日期',aggfunc='sum',margins=True)
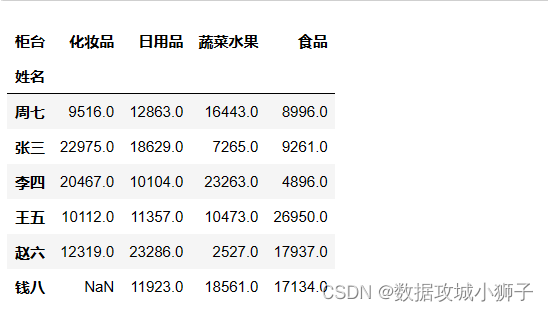
#每人在各柜台的交易总额
dff=df.groupby(by=['姓名','柜台'],as_index=False).sum()
dff.pivot(index='姓名',columns='柜台',values='交易额')
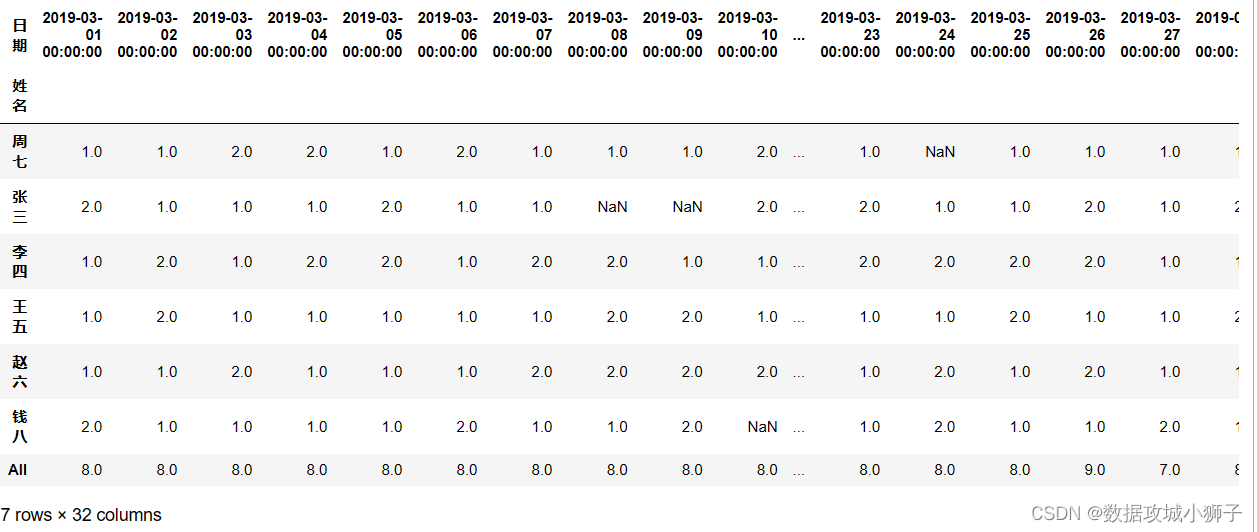
#每人每天上班次数
df.pivot_table(values='交易额',index='姓名',columns='日期',aggfunc='count',margins=True)
#每人在各柜台上班次数
df.pivot_table(values='交易额',index='姓名',columns='柜台',aggfunc='count',margins=True)
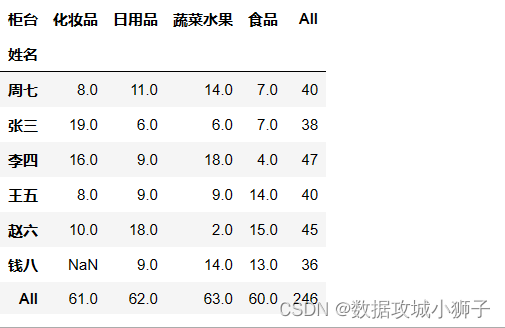
#每人每天上班次数
pd.crosstab(df.姓名,df.日期,margins=True).iloc[:,:5]
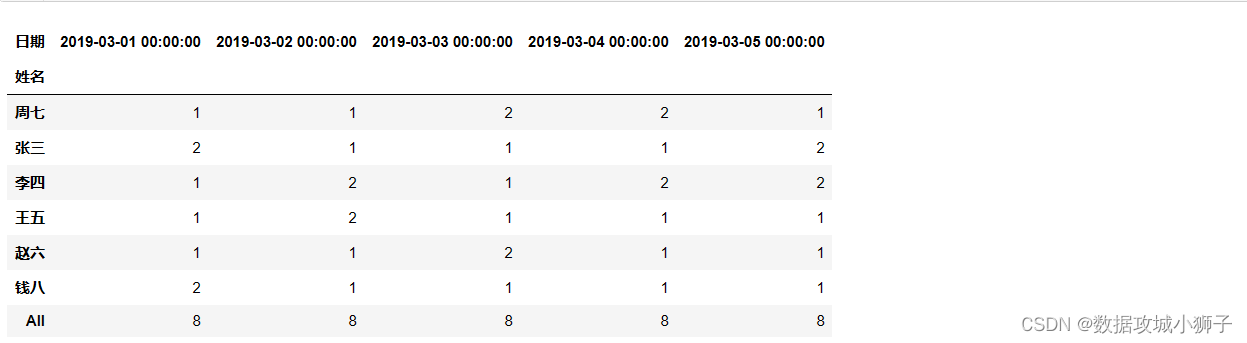
#每人在各柜台上班总次数
pd.crosstab(df.姓名,df.柜台,margins=True)
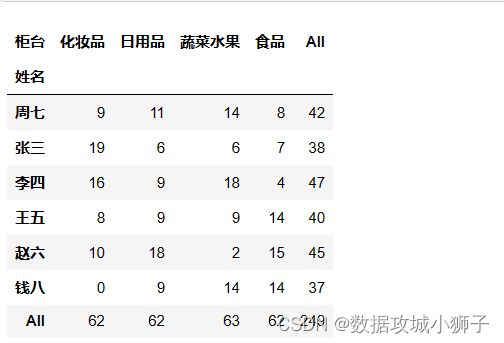
#每人在各柜台交易总额
pd.crosstab(df.姓名,df.柜台,df.交易额,aggfunc='sum')
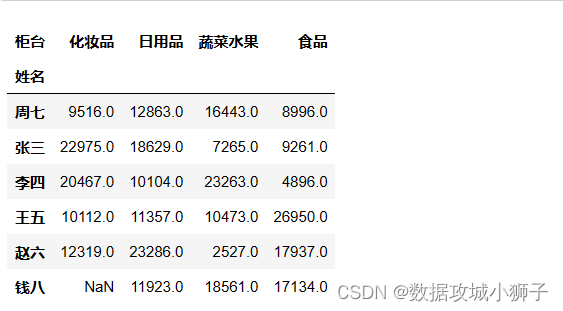
#每人在各柜台交易额平均值
pd.crosstab(df.姓名,df.柜台,df.交易额,aggfunc='mean').apply(lambda num:round(num,2))#保留两位小数

使用重采样技术按时间段查看员工业绩
重采样时间间隔 7D表示每7天采样一次。
label='left’表示使用采样周期的起始时间作为结果DataFrame的index;label='right’表示使用采样周期的结束时间作为结果DataFrame的index;
on指定根据哪一列进行重采样,要求该列数据为日期时间类型。
df.日期=pd.to_datetime(df.日期)
#每7天营业总额
df.resample('7D',on='日期').sum()['交易额']

#每7天营业总额
df.resample('7D',on='日期',label='right').sum()['交易额']
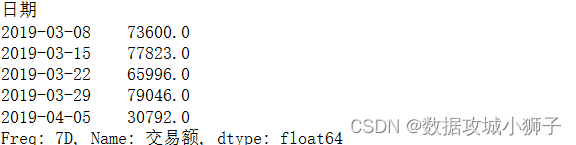
#每7天营业额平均值
func=lambda num:round(num,2)
df.resample('7D',on='日期',label='right').mean().apply(func)['交易额']

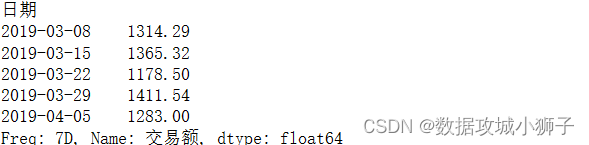
#每7天营业额平均值
import numpy as np
func=lambda item:round(np.sum(item)/len(item),2)
df.resample('7D',on='日期',label='right')['交易额'].apply(func)
相关内容
热门资讯
linux入门---制作进度条
了解缓冲区 我们首先来看看下面的操作: 我们首先创建了一个文件并在这个文件里面添加了...
C++ 机房预约系统(六):学...
8、 学生模块 8.1 学生子菜单、登录和注销 实现步骤: 在Student.cpp的...
JAVA多线程知识整理
Java多线程基础 线程的创建和启动 继承Thread类来创建并启动 自定义Thread类的子类&#...
【洛谷 P1090】[NOIP...
[NOIP2004 提高组] 合并果子 / [USACO06NOV] Fence Repair G ...
国民技术LPUART介绍
低功耗通用异步接收器(LPUART) 简介 低功耗通用异步收发器...
城乡供水一体化平台-助力乡村振...
城乡供水一体化管理系统建设方案 城乡供水一体化管理系统是运用云计算、大数据等信息化手段...
程序的循环结构和random库...
第三个参数就是步长 引入文件时记得指明字符格式,否则读入不了 ...
中国版ChatGPT在哪些方面...
目录 一、中国巨大的市场需求 二、中国企业加速创新 三、中国的人工智能发展 四、企业愿景的推进 五、...
报名开启 | 共赴一场 Flu...
2023 年 1 月 25 日,Flutter Forward 大会在肯尼亚首都内罗毕...
汇编00-MASM 和 Vis...
Qt源码解析 索引 汇编逆向--- MASM 和 Visual Studio入门 前提知识ÿ...
【简陋Web应用3】实现人脸比...
文章目录🍉 前情提要🌷 效果演示🥝 实现过程1. u...
前缀和与对数器与二分法
1. 前缀和 假设有一个数组,我们想大量频繁的去访问L到R这个区间的和,...
windows安装JDK步骤
一、 下载JDK安装包 下载地址:https://www.oracle.com/jav...
分治法实现合并排序(归并排序)...
🎊【数据结构与算法】专题正在持续更新中,各种数据结构的创建原理与运用✨...
在linux上安装配置node...
目录前言1,关于nodejs2,配置环境变量3,总结 前言...
Linux学习之端口、网络协议...
端口:设备与外界通讯交流的出口 网络协议: 网络协议是指计算机通信网...
Linux内核进程管理并发同步...
并发同步并发 是指在某一时间段内能够处理多个任务的能力,而 并行 是指同一时间能够处理...
opencv学习-HOG LO...
目录1. HOG(Histogram of Oriented Gradients,方向梯度直方图)1...
EEG微状态的功能意义
导读大脑的瞬时全局功能状态反映在其电场结构上。聚类分析方法一致地提取了四种头表面脑电场结构ÿ...
【Unity 手写PBR】Bu...
写在前面 前期积累: GAMES101作业7提高-实现微表面模型你需要了解的知识 【技...