NLP 数据增强
1. 基于 Word-Embeddings 的替换
采用预先训练好的词向量,如 Word2Vec、GloVe、FastText,用向量空间中距离最近的单词替换原始句子中的单词。 Jiao等人在他们的论文 “TinyBert” 中使用了这种方法,以改进语言模型在下游任务上的泛化性;Wang 等人使用它来对 tweet 语料进行数据增强来学习主题模型。

# pip install gensim
import gensim.downloader as apimodel = api.load('glove-twitter-25')
model.most_similar('awesome', topn=5)
运行结果:
[('amazing', 0.9687871932983398),('best', 0.9600659608840942),('fun', 0.9331520795822144),('fantastic', 0.9313924312591553),('perfect', 0.9243415594100952)]
2. 基于 Masked Language Model 的替换
像 BERT、ROBERTA 和 ALBERT 这样基于 Transformer 的模型已经使用 “Masked Language Modeling” 的方式,即模型要根据上下文来预测被 Mask 的词语,通过这种方式在大规模的文本上进行预训练。
Masked Language Modeling 同样可以用来做文本的数据增强。例如,可以使用一个预先训练好的 BERT 模型,然后对文本的某些部分进行 Mask,让 BERT 模型预测被 Mask 的词语。
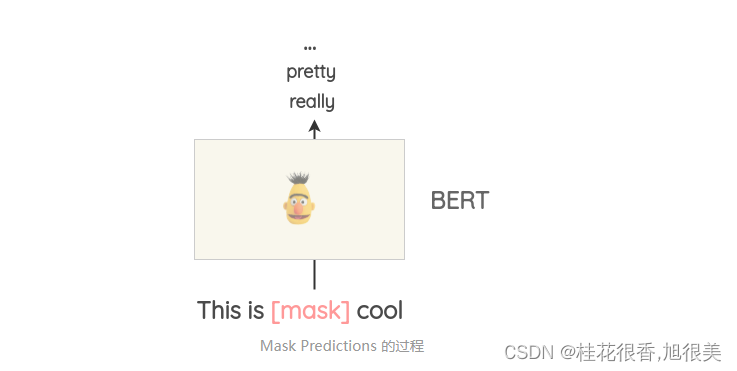
这种方法叫 Mask Predictions。和之前的方法相比,这种方法生成的文本在语法上更加通顺,因为模型在进行预测的时候考虑了上下文信息。可以很方便的使用 HuggingFace 的 transfomers 库,通过设置要替换的词语并生成预测来做文本的数据增强。

from transformers import pipeline
nlp = pipeline('fill-mask')
nlp('This is cool')output:
[{'score': 0.515411913394928,'sequence': ' This is pretty cool','token': 1256},{'score': 0.1166248694062233,'sequence': ' This is really cool','token': 269},{'score': 0.07387523353099823,'sequence': ' This is super cool','token': 2422},{'score': 0.04272908344864845,'sequence': ' This is kinda cool','token': 24282},{'score': 0.034715913236141205,'sequence': ' This is very cool','token': 182}]
然而,这种方法的一个需要注意的地方是如何确定要 Mask 文本的哪一部分,一般需要使用启发式的方法来决定 Mask 的地方,否则生成的文本可能无法保留原句的含义。
3. 基于 TF-IDF 的替换
TF-IDF 分数较低的单词(停用词)不能提供信息,因此可以在不影响句子的基本真值标签的情况下替换它们。

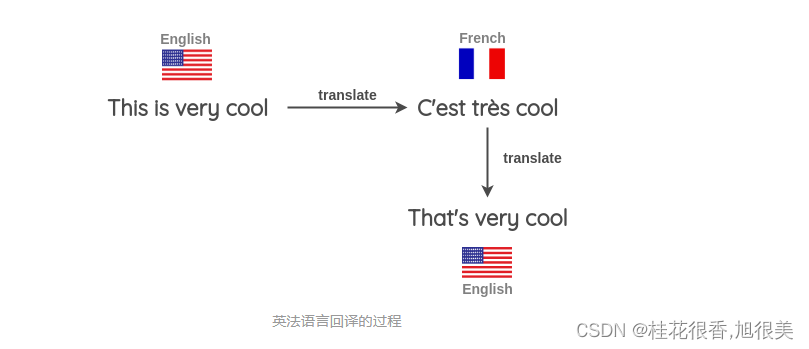
4. Back Translation(回译)
- 找一些句子(如英语),翻译成另一种语言,如法语
- 把法语句子翻译成英语句子
- 检查新句子是否与原来的句子不同。如果是,那么我们使用这个新句子作为原始文本的补充版本。
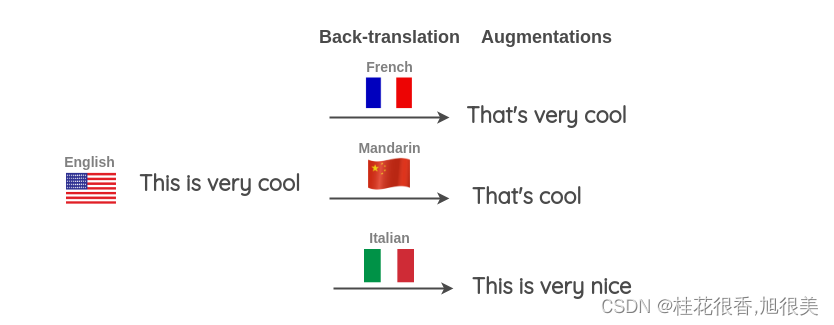
还可以同时使用多种不同的语言来进行回译以生成更多的文本变体。如下图所示,将一个英语句子翻译成目标语言,然后再将其翻译成三种目标语言:法语、汉语和意大利语。
对于如何实现回译,可以使用 TextBlob 或者谷歌翻译API。
5. 生成式的方法
尝试在生成额外的训练数据的同时保留原始类别的标签。
Conditional Pre-trained Language Models
这种方法最早是由 Anaby-Tavor 等人在他们的论文 “Not Enough Data? Deep Learning to the Rescue!” Kumar等人最近的一篇论文在多个基于 Transformer 的预训练模型中验证了这一想法。
问题的表述如下:
- 在训练数据中预先加入类别标签,如下图所示。

- 在这个修改过的训练数据上 finetune 一个大型的预训练语言模型 (BERT/GPT2/BART) 。对于 GPT2,目标是去做生成任务;而对于 BERT,目标是要去预测被 Mask 的词语。

- 使用经过 finetune 的语言模型,可以使用类标签和几个初始单词作为模型的提示词来生成新的数据。本文使用每条训练数据的前 3 个初始词来为训练数据做数据增强。

nlpaug 和 textattack 等第三方 Python 库提供了简单易用的 API,可以轻松使用上面介绍的 NLP 数据增强方法。
6. 改写(paraphrase)
在线改写工具 
finetune gpt2 or T5