搭建Hadoop2.9伪分布集群环境
搭建Hadoop2.9伪分布集群环境
自己创建一个普通用户,用普通用户登录或者用root登录也可以的,具体根据公司的要求来
systemctl stop firewalld
systemctl disable firewalld
useradd hadoop1 #我创建的用户是hadoop
passwd hadoop1 #这里输入用户hadoop的密码,连续输入2次
cat >> /etc/hosts << EOF
192.168.243.190 hadoop1
EOF
su - hadoop1 #替换到hadoop下开始安装
ssh-keygen -t rsa #命令生成密钥对,一路回车就可以了
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
chmod 700 ~/.ssh/ && chmod 600 ~/.ssh/*
如下所需要的安装包hadoop-2.9.2.tar.gz jdk-8u141-linux-x64.tar.gz下载路径: 链接:https://pan.baidu.com/s/1tgi6-WV31O7X7MhA-MPglw?pwd=6666 提取码:6666 --来自百度网盘超级会员V6的分享
1.JDK安装与配置
[hadoop@hadoop1 ~]$ cd /home/hadoop/
[hadoop@hadoop1 ~]$ mkdir app/
[hadoop@hadoop1 app]$ cd app/
[hadoop@hadoop1 app]$ pwd #jdk和hadoop上传到此目录
/home/hadoop/app
[hadoop@hadoop1 app]$ ls
hadoop-2.9.2.tar.gz jdk-8u141-linux-x64.tar.gz
[hadoop@hadoop1 app]$ tar -zxvf jdk-8u141-linux-x64.tar.gz
[hadoop@hadoop1 app]$ ln -s jdk1.8.0_141 jdk
[hadoop@hadoop1 app]$ ls
hadoop-2.9.2.tar.gz jdk jdk1.8.0_141 jdk-8u141-linux-x64.tar.gz
[hadoop@hadoop1 app]$ cat >> ~/.bashrc << EOF
JAVA_HOME=/home/hadoop/app/jdk
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
EOF
[hadoop@hadoop1 app]$ source ~/.bashrc
[hadoop@hadoop1 app]$ echo $JAVA_HOME
/home/hadoop/app/jdk
[hadoop@hadoop1 app]$ java -version
openjdk version "1.8.0_262"
OpenJDK Runtime Environment (build 1.8.0_262-b10)
OpenJDK 64-Bit Server VM (build 25.262-b10, mixed mode)
[hadoop@hadoop1 app]$ 2.Hadoop的安装与配置
2.1上传和解压Hadoop
[hadoop@hadoop1 app]$ pwd #把hadoop安装包上传到这里,我已经在上一步上传了
/home/hadoop/app
[hadoop@hadoop1 app]$ ls
hadoop-2.9.2.tar.gz jdk jdk1.8.0_141 jdk-8u141-linux-x64.tar.gz
[hadoop@hadoop1 app]$ tar -zxvf hadoop-2.9.2.tar.gz
[hadoop@hadoop1 app]$ ln -s hadoop-2.9.2 hadoop
[hadoop@hadoop1 app]$ ls
hadoop hadoop-2.9.2 hadoop-2.9.2.tar.gz jdk jdk1.8.0_141 jdk-8u141-linux-x64.tar.gz
[hadoop@hadoop1 app]$
2.2配置Hadoop
在hadoop安装目录下进入到etc/hadoop目录,修改Hadoop相关配置文件。
1)修改core-site.xml配置文件。
core-site.xml文件主要配置Hadoop的公有属性,具体配置内容如下所示。
[hadoop@hadoop1 hadoop]$ cd /home/hadoop/app/hadoop/etc/hadoop
[hadoop@hadoop1 hadoop]$ vi core-site.xml #中间添加如下的信息
fs.defaultFS hdfs://hadoop1:9000
hadoop.tmp.dir /home/hadoop/data/tmp
2)修改hdfs-site.xml 配置文件。
hdfs-site.xml文件主要配置跟HDFS相关的属性,具体配置内容如下所示。
[hadoop@hadoop1 hadoop]$ vi hdfs-site.xml #中间添加如下的信息
dfs.namenode.name.dir /home/hadoop/data/dfs/name
dfs.datanode.data.dir /home/hadoop/data/dfs/data
dfs.replication 1
dfs.permissions false
3)修改hadoop-env.sh配置文件。
hadoop-env.sh文件主要配置跟hadoop环境相关的变量,这里主要修改JAVA_HOME的安装目录,具体配置内容如下所示。
[hadoop@hadoop1 hadoop]$ vi hadoop-env.sh #修改里面的这个环境路径
export JAVA_HOME=/home/hadoop/app/jdk
4)修改mapred-site.xml配置文件。
mapred-site.xml 文件主要配置跟MapReduce 相关的属性,这里主要将MapReduce的运行框架名称配置为YARN,具体配置内容如下所示。
[hadoop@hadoop1 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@hadoop1 hadoop]$ vi mapred-site.xml #中间添加如下的信息
mapreduce.framework.name yarn
5)修改 yarn-site.xml配置文件。
yarn-site.xml文件主要配置跟YARN 相关的属性,具体配置内容如下所示。
[hadoop@hadoop1 hadoop]$ vi yarn-site.xml #中间添加如下的信息
yarn.nodemanager.aux-services mapreduce_shuffle
6)修改slaves配置文件。
slaves文件主要配置哪些节点为datanode角色,由于目前搭建的是Hadoop伪分布集群,所以只需要填写当前主机的hostname即可,具体配置内容如下所示。
[hadoop@hadoop1 hadoop]$ vi slaves #修改为你服务器的hostname,不能有回车等
hadoop
7)配置Hadoop环境变量。
在hadoop用户下,添加Hadoop环境变量,具体操作如下所示。
[hadoop@hadoop1 hadoop]$ vi ~/.bashrc #添加如下信息
export HADOOP_HOME=/home/hadoop/app/hadoop
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
[hadoop@hadoop1 hadoop]$ source ~/.bashrc
[hadoop@hadoop1 hadoop]$ hadoop version
Hadoop 2.9.2
8)创建Hadoop相关数据目录。
在hadoop用户下,创建Hadoop相关数据目录,具体操作如下所示。
mkdir -p /home/hadoop/data/tmp
mkdir -p /home/hadoop/data/dfs/name
mkdir -p /home/hadoop/data/dfs/data
2.3启动Hadoop伪分布集群
(1)格式化主节点namenode
在Hadoop安装目录下,使用如下命令对NameNode进行格式化。
[hadoop@hadoop1 hadoop]$ /home/hadoop/app/hadoop
[hadoop@hadoop1 hadoop]$ bin/hdfs namenode -format
注意:第一次安装Hadoop集群需要对NameNode进行格式化,Hadoop集群安装成功之后,下次只需要使用脚本start-all.sh一键启动Hadoop集群即可。
(2)启动Hadoop伪分布集群
在Hadoop安装目录下,使用脚本一键启动Hadoop集群,具体操作如下所示。
[hadoop@hadoop1 hadoop]$ sbin/start-all.sh
(3)查看Hadoop服务进程
通过jps命令查看Hadoop伪分布集群的服务进程,具体操作如下所示。
[hadoop@hadoop1 hadoop]$ jps
[hadoop@hadoop1 hadoop]$ jps
55412 Jps
53815 SecondaryNameNode
53627 DataNode
53979 ResourceManager
54571 NameNode
54285 NodeManager
[hadoop@hadoop1 hadoop]$ 如果服务进程中包含Resourcemanager、Nodemanager、NameNode、DataNode和SecondaryNameNode等5个进程,这就说明Hadoop伪分布集群启动成功。
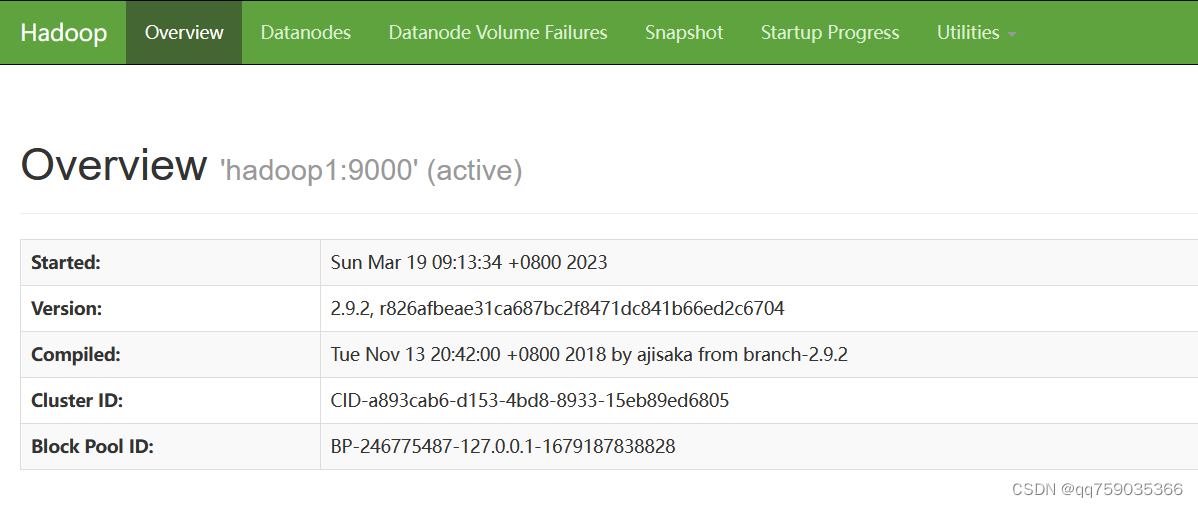
(4)查看HDFS文件系统
在浏览器中输入http://192.168.243.190:50070/地址,通过web界面查看HDFS文件系统,具体操作图下图所示:
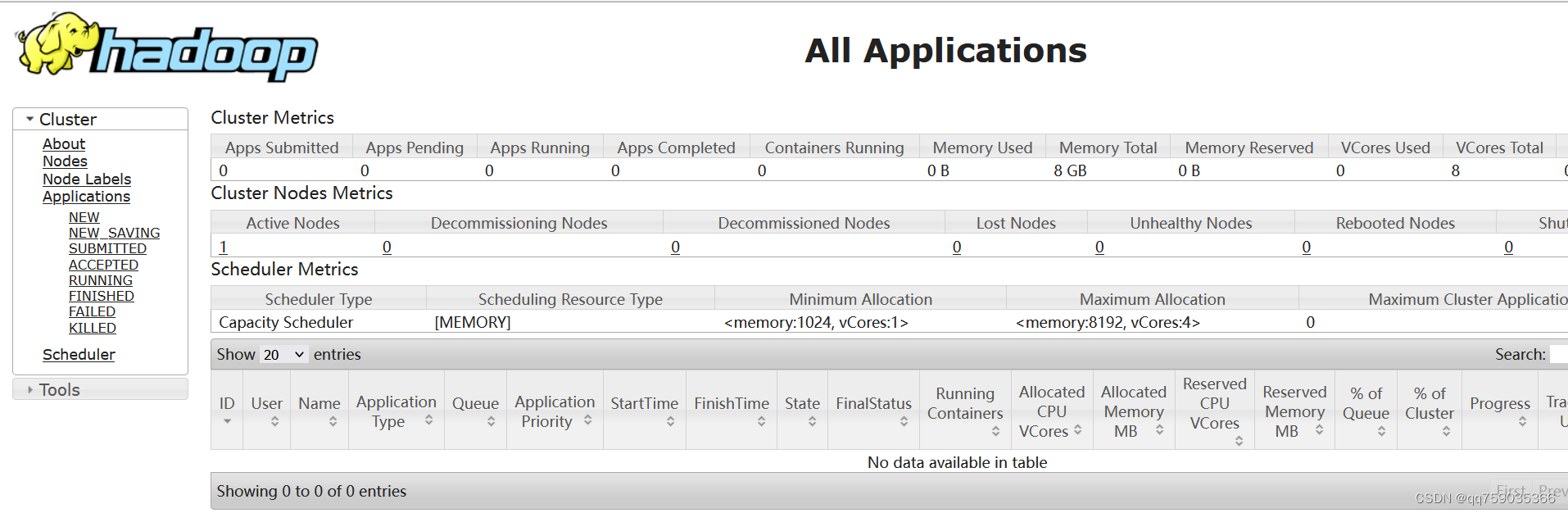
(5)查看YARN资源管理系统
在浏览器中输入http://192.168.243.190:8088/地址,通过web界面查看YARN资源管理系统,具体操作如下图所示。
2.4测试运行Hadoop伪分布集群
Hadoop伪分布集群启动之后,我们以Hadoop自带的WordCount案例来检测Hadoop集群环境的可用性。
(1)查看HDFS目录
在HDFS shell中,使用ls命令查看HDFS文件系统目录,具体操作如下所示。
[hadoop@hadoop1 hadoop]$ bin/hdfs dfs -ls /
由于是第一次使用HDFS文件系统,所以HDFS中目前没有任何目录和文件。
(2)创建HDFS目录
在HDFS shell中,使用mkdir命令创建HDFS文件目录/test,具体操作如下所示。
[hadoop@hadoop1 hadoop]$ bin/hdfs dfs -mkdir /test
(3)准备测试数据集
在Hadoop根目录下,新建words.log文件并输入测试数据,具体操作如下所示。
[hadoop@hadoop1 hadoop]$ vi words.log
hadoop hadoop hadoop
spark spark spark
flink flink flink
(4)测试数据上传至HDFS
使用put命令将words.log文件上传至HDFS的/test目录下,具体操作如下所示。
[hadoop@hadoop1 hadoop]$ bin/hdfs dfs -put words.log /test
(5)运行WordCount案例
使用yarn脚本将Hadoop自带的WordCount程序提交到YARN集群运行,具体操作如下所示。
[hadoop@hadoop1 hadoop]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /test/words.log /test/out
(6)查看作业运行状态
在浏览器中输入http://192.168.243.190:8088/地址,通过web界面查看YARN中作业运行状态,具体操作如图下图所示。
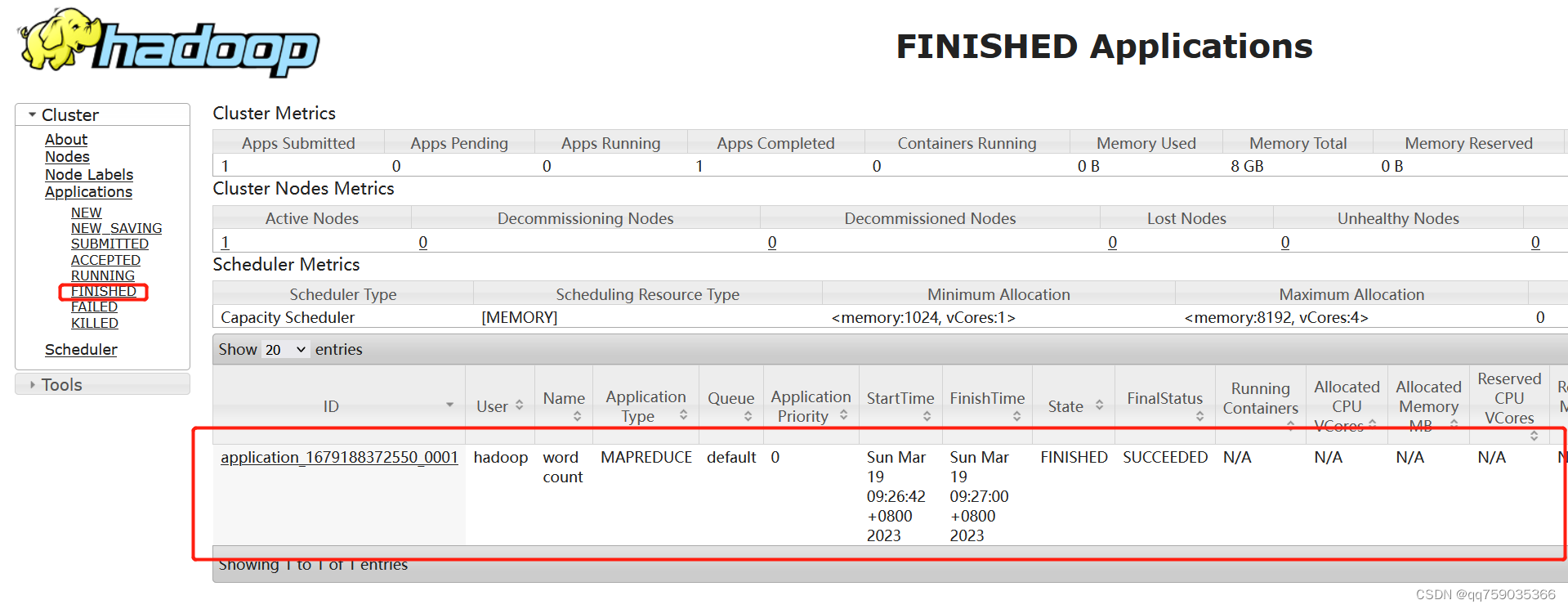
如果在YARN 集群的Web界面中,查看到WordCount作业最终的运行状态为SUCCESS,就说明MapReduce程序可以在YARN集群上成功运行。
(7)查询作业运行结果
使用cat命令查看WordCount作业输出结果,具体操作如下所示。
[hadoop@hadoop1 hadoop]$ bin/hdfs dfs -cat /test/out/*
flink 3
hadoop 3
spark 3
如果WordCount运行结果符合预期值,说明Hadoop伪分布式集群已经搭建成功!
上一篇:P6专题:聊聊项目的几种状态类型
下一篇:C语言实现链表