两阶段提交(two phase commit,2PC)故障恢复原理分析
两阶段提交(two phase commit,2PC)故障恢复原理分析
archimekai
目录
两阶段提交(two phase commit,2PC)故障恢复原理分析... 1
前言... 1
两阶段提交介绍... 1
两阶段提交的基本流程... 1
2PC状态机... 3
小结:2PC中需要持久化的状态... 4
备注... 5
两阶段提交的故障恢复... 5
两阶段提交协议具有safety属性... 7
两阶段提交协议具有liveness属性... 7
前言
很多分布式方面的书籍和网络上的很多博客都有关于两阶段提交的介绍。但是遗憾的是,大部分文章只介绍了两阶段提交在正常状况下的处理流程,并未介绍出现故障时,两阶段提交如何进行故障恢复,确保事务的正确性。这就好像上了一道宫爆鸡丁,只是把其中的花生吃掉了,但是没有吃鸡丁,让读者读后无法掌握两阶段提交的精髓。
基于此,笔者试图较为完整地介绍基本的两阶段提交协议,特别是介绍其日志机制,以及两阶段提交协议在面对进程重启(Failure,F)和网络超时(Timeout, T)这两种典型故障时是如何进行故障恢复的,以帮助读者全面掌握两阶段提交。
两阶段提交有许多变种和优化手段,根据本文的反馈,笔者后面可能会展开介绍。
本文的主要参考资料是《Transactional Information Systems: Theory, Algorithms, and the Practice of Concurrency Control and Recovery》
TODO:增加一些具体的例子,让本文更易于理解。
两阶段提交介绍
两阶段提交的基本流程
两阶段提交(two phase commit,2PC)是保证分布式事务原子性的技术之一:或者事务在所有参与者上都提交,或者所有参与者上都不提交。两阶段提交中最主要的两个角色是coordinator和participant,其中coordinator负责在全局范围内协调participant并推进事务的进程,participant则负责执行具体的事务操作,执行并响应coordinator的命令。
coordinator通过如下两个阶段(如图 1所示)确保事务要么在全部participants上提交,要么在全部participants上回滚。
阶段一:准备阶段。coordinator询问每一个participant是否准备好提交事务。如果participant已经完成prepare日志(类似于redo日志,但是尚未提交)持久化,就可以回复“prepared“。如果participant因为某些原因无法提交事务(例如无法获得资源上的锁),就回答”no“。
阶段二:决定阶段。决定事务是提交还是回滚。如果coordinator发现所有participants回答都为”prepared“,就可以发布提交命令。如果有至少一个participant回答”no“,coordinator就要发布回滚命令。无论收到哪个命令,participant都要向coordinator回复一个ack消息来确认自己成功执行了命令。
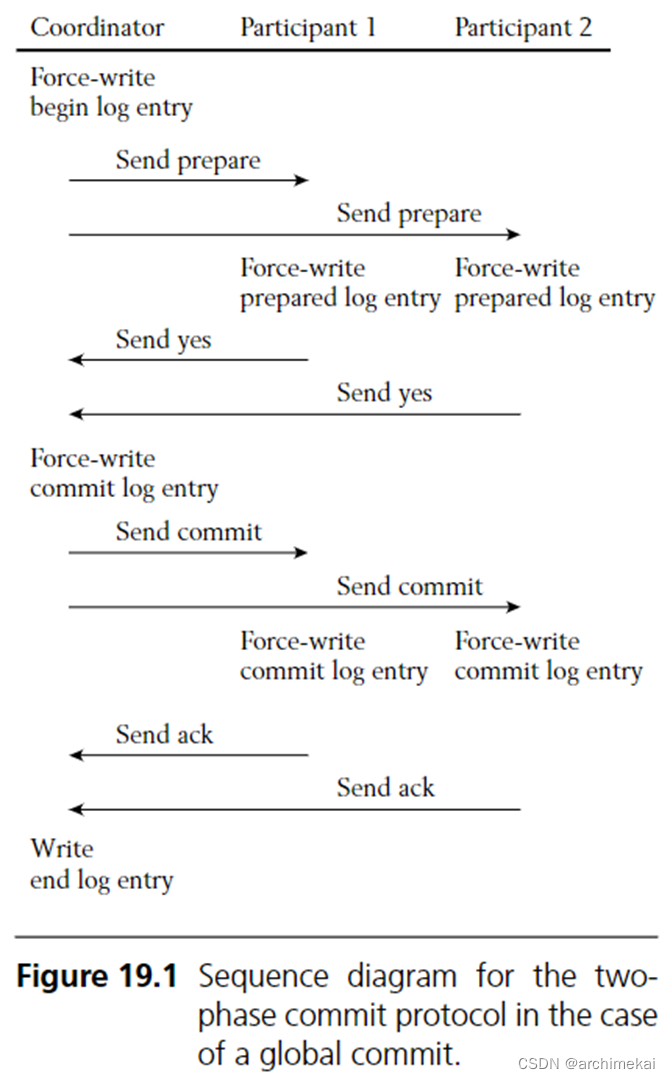
图 1 两阶段提交时序图。Force write代表日志必须落盘后才能继续后面的处理流程。
两阶段提交需要合理应对各种意外情况,例如:
- 消息丢失
- 消息重复
- coordinator和participant都可能在任意时刻宕机
消息丢失的问题可以通过对所有(特殊消息以外的)消息都自动生成一个特殊回复消息来解决,如果发送方没有收到这个特殊回复消息,就重复发送消息。
消息重复的问题可以通过消息上的序列号来解决。
虽然TCP/IP协议已经具有上述机制,能够避免消息丢失和消息重复,但是2PC协议所遇到的上述两个问题不能通过使用TCP/IP协议解决(主要是由于coordinator和participant进程都可能会故障,并重启为一个新的进程)。因此,2PC协议不对通信系统做任何假设。
为了解决宕机的问题,当participant从宕机中重启后,需要先和coordinator确认当前事务的状态,然后依据后文介绍的恢复流程进行恢复。
2PC状态机
2PC对应的状态机如图 2所示。每个椭圆代表一个状态。每个状态代表一条特定的日志记录。只有当日志文件中保存了相应的日志记录后,进程才进入该状态。例如,coordinator的Forgotten状态代表日志中存在end日志。
状态之间的转换采用事件-条件-动作(event-condition-action,ECA)标记在箭头上,形式如”事件 [条件]/动作“,ECA中的一些元素在图中未被标注,读者应该可以轻松推断出来。当指定的事件发生,并且指定的条件为真时,就会触发状态机的状态变更,状态机从旧状态进入新状态。
在2PC中,事件指接收到某个消息,动作指发出某个消息。例如,图中左上角的一个箭头上标记了“Prepare1/yes1”,表示当(正处于Initial1的)Participant1接收到(来自Coordinator的)Prepare1消息后,会进行事务的prepare,然后进入Prepared1状态,最后回复Coordinator yes1消息。
图 2中展示了三个正交的组件,每个组件代表2PC中的一个进程。这些进程可以并行运行,但是需要在合适的时机等待消息交换。图中的两个participant事实上是一样的,可以被当作一个状态机的两个实例。为了后面描述清晰,我们特地在图中以1,2的后缀进行区分。
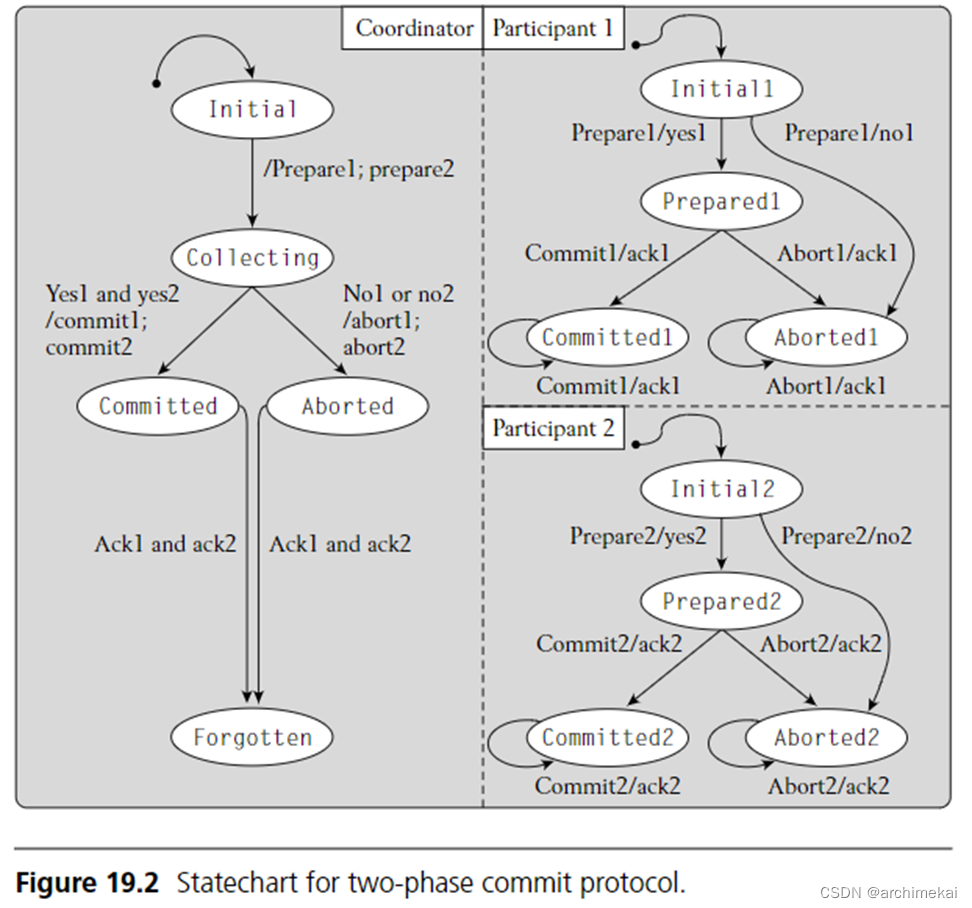
图 2 两阶段提交的状态机
小结:2PC中需要持久化的状态
coordinator需要持久化如下状态:
- 所有参与本次2PC的participant,一般记录在begin日志中
- 在询问participant是否准备好提交事务前,记录一条begin日志
- 第二阶段接收到所有participant的ack响应后,记录一条end日志
end日志记录后,coordinator就进入forgotten状态,这意味着coordinator上和本次2PC相关的日志可以被删除。这样可以控制coordinator的日志大小,加速coordinator的重启
participant需要记录如下日志:
- 本次2PC的coordinator,可以记录在prepare日志中
- 准备阶段要记录prepare日志
- 接收到coordinator的提交或回滚命令时,需要持久化相应的日志
上述日志的目的是记录进程在本次2PC中的状态,
备注
2PC是一个阻塞式的协议:当participant回复prepared后,如果coordinator一直不发送是否提交事务的决定,participant会被阻塞。2PC是一个阻塞式的协议:当participant回复prepared后,如果coordinator一直不发送是否提交事务的决定,participant会被阻塞,被阻塞的participant不能释放已经prepared事务所持有的锁等资源。
两阶段提交的故障恢复
两阶段提交中,coordinator和participant都会在状态机发生状态变化的同时,将新状态持久化。这样,当coordinator或participant重启时,就可以从被记住的状态处继续。
为了保证两阶段提交中的故障恢复,可以按如下方式扩展两阶段提交:
- 新增重启处理(Fault, F)流程,当coordinator或participant重启时,执行此流程。
- 新增超时处理(Timeout, T)流程,当coordinator或participant等待消息超时时,执行此流程。需要注意的是,探测到超时时,并不能区分是对端故障,还是网络故障,超时处理流程需要能同时应对这两种情况。
当进程意外结束后,重启进程时,基于持久化保存的状态机状态触发对应的F流程。例如,当participant重启后,可以从日志文件中最近的日志为prepare日志来确定自己处于prepared状态,这样participant可以再次发送“prepared“响应给coordinator,并等待coordinator对于事务是否提交的回复。再例如,当coordinator重启后,其可以从日志文件中最近的日志为begin日志来确定自己处于Initial状态,coordinator可以重新询问每一个participant是否准备好提交事务。
当等待对端消息超时时,触发T流程。
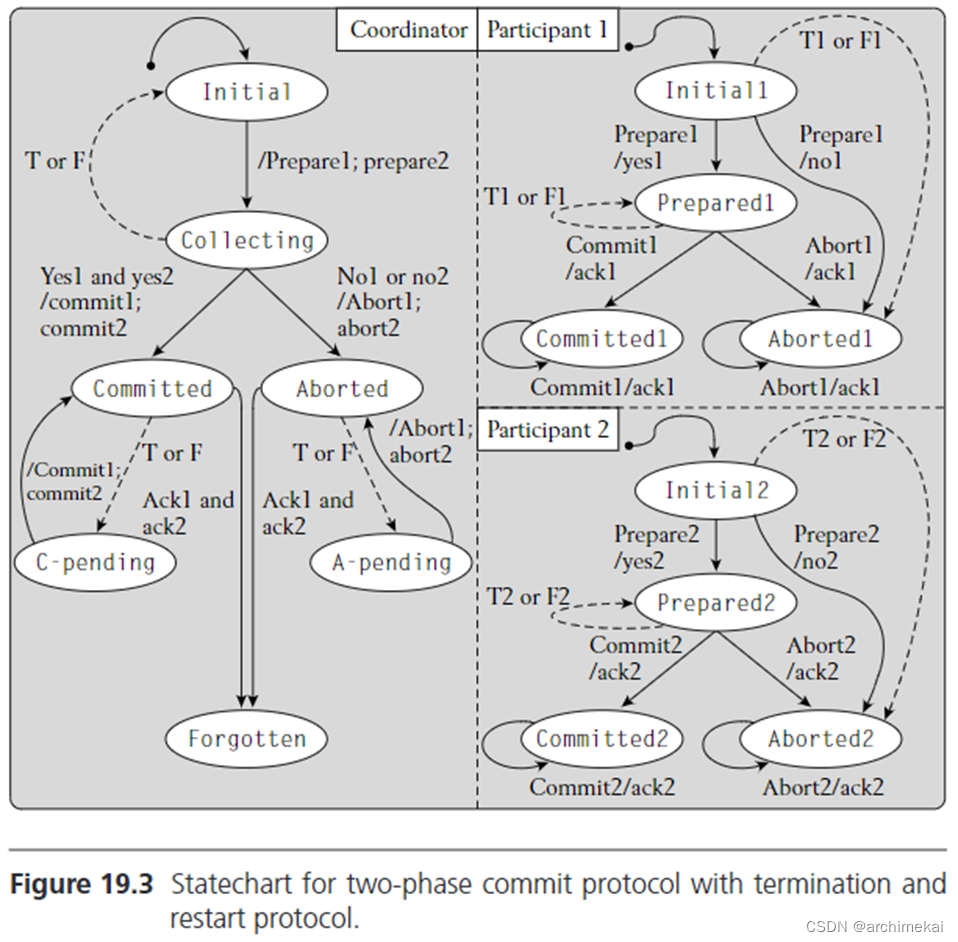
图 3 两阶段提交的故障恢复
带有上述恢复流程的2PC活动图如图 3所示。重启处理流程和超时处理流程对于达成全局一致的事务提交和回滚是至关重要的:
- coordinator重启流程:
- 在initial状态失败(T)重启后:coordinator自动从头初始化该两阶段提交。
- 在collecting状态失败重启后:由于coordinator不确定曾经接收到了来自哪些participant的回复,coordinator需要重新回到initial状态,重新询问participants是否准备好提交事务
- 在Committed或Aborted状态失败重启后:coordinator重新向participants发送commit或者abort消息(可能会和之前发送的重复),并等待participants的ack消息。
- coordinator超时流程:
- 当coordinator长时间未接收到某个participant的消息时,其会根据所处的状态重新发送对应的消息,和上面的coordinator重启流程类似。coordinator可以只发送消息给超时的participants。
- Participant重启流程:
- 当participant从Initial状态失败重启后:participant可以自由决定是否参与此次2PC,也即,当后续收到Coordinator的Prepare消息时,可以自由回复yes或no。回复no的好处是,可以避免participant长时间占用资源(例如锁)释放。
- 当participant从Prepared状态失败重启后:participant等待coordinator重新发过来消息,并对coordinator做出适当的回答(如果coordinator发来prepare消息,则participant回复yes,如果coordinator发来commit消息或abort消息,则participant回复ack)
- Participant超时流程:
- Participant的超时流程和上述重启流程基本一致。一个优化是,处在Initial状态的Participant可以允许更长的超时时间,从而避免过早执行恢复动作。
需要注意的是,在Forgotten状态下,无需执行任何恢复操作(2PC已经结束了)。还有一些状态需要额外的辅助状态来进行故障恢复(例如A-pending,C-pending),不过这些辅助状态不需要持久化。
两阶段提交协议具有safety属性
分布式系统中,某个协议(算法)的safety指的是执行该协议时不会发生预料之外的事情(nothing bad will ever happen)
定理1:两阶段提交协议能够保证分布式事务的原子性。也就是说,如果coordinator或任何一个participant进入了终止状态,那么所有的participant和coordinator或者都进入Committed状态,或者都进入Aborted状态。(为了简单起见,此处忽略Forgotten状态)
证明请见 《Transactional Information Systems: Theory, Algorithms, and the Practice of Concurrency Control and Recovery》第738页。
两阶段提交协议具有liveness属性
分布式系统中,某个协议的liveness指的是该协议最终一定能执行完毕(something good will eventually happen)。
定理2:对于有限次数的故障(例如进程故障并重启,消息丢失等),两阶段提交协议能在有限次数的状态转换后进入全局终止状态。全局终止状态指或者所有的participants都处于Committed状态,或者所有的participants都处于Aborted状态。
证明请见 《Transactional Information Systems: Theory, Algorithms, and the Practice of Concurrency Control and Recovery》第740页。