论文阅读Spectral Unsupervised Domain Adaptation for Visual Recognition
1 论文简介
1.1 论文标题
Spectral Unsupervised Domain Adaptation for Visual Recognition
1.2 论文发表位置
CVPR2022
IEEE/CVF Conference on Computer Vision and Pattern Recognition
1.3 论文地址
https://arxiv.org/abs/2106.06112#
1.4 论文署名单位
Nanyang Technological University 南洋理工大学NTU
qs ranking: 12
1.5 论文代码未公开
1.6 实验设备未提及
2 摘要
2.1 任务
无监督跨域自适应任务UDA
UDA指的是将从带标签的原始域中学习到的知识应用到没有标签的目标域中解决相似的问题
2.2 提出解决办法
该论文提出了Spectral UDA方法,这个方法在时域中处理图像数据,并且在不同的任务上都表现尚可
该论文首先提出了时域transformer(Spectral Transformer),通过增强跨域不变的特征,抑制跨域变化的特征来减轻域间差异的影响。
其次论文中引入了多视野时域学习方法(multi-view spectral learning),该方法可以学习到有用的无监督特征。
更具体一点来说,该方法首先使用多个时域transformer,针对每个目标域样本target sample生成多个视野的特征;最后最大化这些不同视野的特征之间的互信息。
2.4 实验
实验结果显示SHOT在多个跨域任务上(包含图像分类、语义分割、目标检测)达到了SOTA
5 方法Method
5.1 概览overview
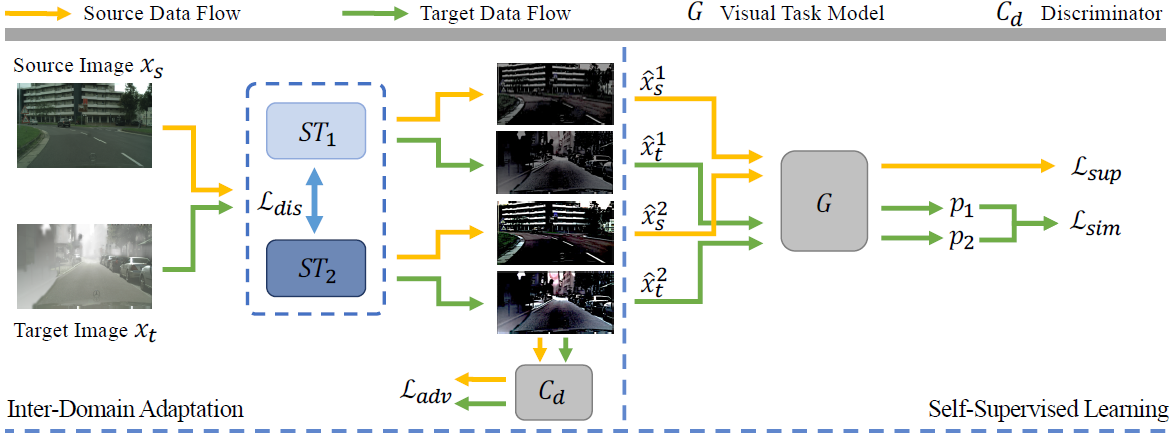
以上是整体框架图。\
- 首先,从原始域数据集和目标域数据集从采样得到原始域数据(source samples Xs, source labels Ys),目标域数据target samples Xt。\
- 然后将他们分别输入时域transformer特征提取器ST1和ST2中。Xs送入ST1和ST2分别得到X^s1\hat{X}_{s}^{1}X^s1和X^s2\hat{X}_{s}^{2}X^s2,即图中的浅黄色路径;Xt送入ST1和ST2分别得到X^t1\hat{X}_{t}^{1}X^t1和X^t2\hat{X}_{t}^{2}X^t2,即图中的浅绿色路径。\
- ST1和ST2使用损失函数,Ldis保证他们的参数不同,提取的特征也是不同的,即前面提到的不同视野multi-view,Ldis在实现上采用了参数的余弦相似度,下列参考博客可详细学习余弦相似度。
https://blog.csdn.net/u014539465/article/details/105353638/
-
ST输出的特征X^\hat{X}X^及其对应的域标签domain label会送入判别器CdC_dCd进行对抗学习。ST的目标是输入的特征让判别器无法识别出自哪个域,而判别器的目标是尽量分清楚特征来自于哪一个域,损失函数是LadvL_{adv}Ladv。
-
原始数据的特征X^s1\hat{X}_{s}^{1}X^s1和X^s2\hat{X}_{s}^{2}X^s2送入视觉任务模型G(例如分类任务时是分类器)配合原始域数据标签进行有监督学习,损失函数是LsupL_{sup}Lsup。
-
目标域数据的特征X^t1\hat{X}_{t}^{1}X^t1和X^t2\hat{X}_{t}^{2}X^t2送入视觉任务模型G得到预测结果p1和p2,然后进行自监督学习,通过要求p1和p2相似去增大两个视野(两个ST)之间的互信息(mutual information),损失函数是LsimL_{sim}Lsim,具体实现为p1和p2的差的一范数。
5.2 ST的具体实现

给定一个输入图像(尺寸为[3, H, W]),ST首先使用快速傅里叶变换(Fast Fourier Transform)将其转为频域表示,通过使用带通滤波器,输入图像会被均匀地分解为N个频率分量(frequency components, FCs)每个的形状为[3, 1, H, W]。
分解后的N个频率分量会被送入ST内部的ASA模块(adversarial spectrum attention),自适应地增强跨域不变的频率分量(domain-invariant),抑制跨域易变的频率分量(domain-variant)。