CUDA基础(二)组织并行线程,建立块和线程与矩阵索引的映射。
本文旨在解决如何组织并行线程的问题,讨论块和线程与矩阵索引的映射关系
最后给出,二维grid二维block的最简便通俗易懂的矩阵乘法表示
一、块和线程的(Idx)与矩阵索引(ix,iy),线性内存单元(index)的关系
首先,明确虽然dim3可以有三维,但是任何一维下的映射关系都是同理等价的。所以本文以x维为例。
我们用倒推的方式来理解矩阵乘法和矩阵加法。首先我们大脑里呈现的首先是一个n * m的矩阵——最后加法和乘法得出来的结果矩阵R。
- 对于加法而言,
R的(i,j)即由两个n * m的矩阵对应坐标(i,j)相加而来,一共进行n * m次加法操作,一共需要n * m个线程,即我们知道总线程数 N = n * m - 对于乘法而言,对于R的(i,j)是由第一个矩阵(n * k)的第 i 行和第二个矩阵(k * m)的第 j 列各个元素相加而来——每一个线程需要完成的任务。线程总数N = n * m
当我们得到N (n * m)后 --> (人为)设置blockDim(有最大值1024的限制,取32的整数倍)----> (自动)生成gridDim 。以gridDim.x为例gridDim.x = (n + blcokDim.x - 1) / blockDim.x)
对于一个线程,他的身份就被gridDim和blockDim唯一确定了
可以用以下公式把线程和块索引映射到矩阵坐标上:(这一层映射关系消除了外面两层 for 循环 i 和 j 的开销)
int ix = blockIdx.x * blockDim.x + threadIdx.x;
int iy = blockIdx.y * blockDim.y + threadIdx.y;
在平时写的c语言中(i,j)表示第 i 行 第 j 列。但是在矩阵坐标中(ix,iy)表示第 iy 行,第 ix 列,即和 x、y轴一样的坐标系
但是!
在物理层面:一个矩阵用行优先(x是最低维,y其次,然后是z)的方法在全局内存中进行线性存储
列优先,这是c语言思维(i,j):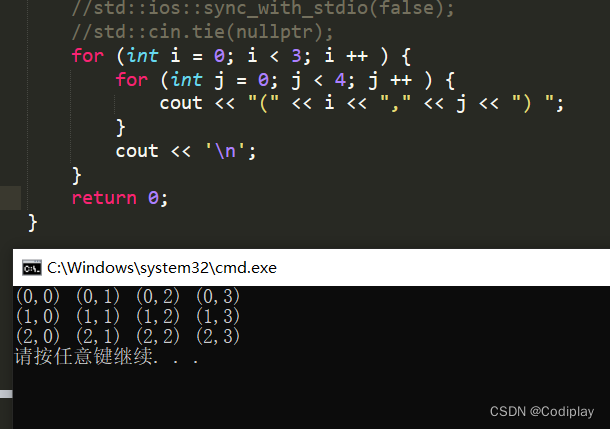
先按行存,行优先,这是实际物理的组织形式(ix,iy):
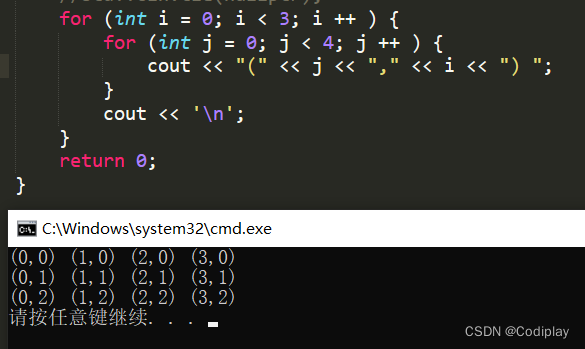
我们要完成以上逻辑的转换
需要完成由线程的逻辑地址到物理地址的映射,将矩阵坐标映射到全局内存的存储单元上,具体公式应为:
index = iy * nx + ix
而我们习惯的方式是index = row * j + col
举个例子:
当位于线程格grid(12,8)的线程块中的(3,5)处的线程开始执行时,他知道在其左边有12个线程块,上方有8个线程块。在这个线程块内,左边有三个线程,上方有5个线程。即有3 + 12 * 16 = 195在其左侧,133在其上侧。
二、网格大小与实际并行工作量不匹配
参考优秀文章:CUDA C/C++ 教程一:加速应用程序
1、网格大于工作量
鉴于 GPU 的硬件特性,线程块中的线程数最好配置为 32 的倍数。但是在实际工作中,很可能会出现这样的情况,我们手动配置参数所创建的线程数无法匹配为实现并行循环所需的线程数,比如实际上需要执行1230次循环,但是你却配置了2048个线程。(你需要保证多配制的线程不能执行核函数)
我们不可能每次配置参数的时候都手动去算一遍最佳配置,更何况并不是所有的数都是 32 的倍数。不过这个问题现在已经可以通过以下三个步骤轻松地解决:
- 首先,设置配置参数,使线程总数超过实际工作所需的线程数。
- 然后,在向核函数传递参数时传递一个用于表示要处理的数据集总大小或完成工作所需的总线程数 N。
- 最后,计算网格内的线程索引后(使用 threadIdx + blockIdx*blockDim),判断该索引是否超过 N,只在不超过的情况下执行与核函数相关的工作。
以下是一种可选的配置方式,适用于 工作总量 N 和线程块中的线程数已知的情况。如此一来,便可确保网格中至少始终能执行 N 次任务,且最多只浪费 1 个线程块的线程数量:
解释一下:便可确保网格中至少始终能执行 N 次任务,且最多只浪费 1 个线程块的线程数量。
number_of_block = (N + threads_per_block - 1) / threads_per_block;这句话是对N / threads_per_block进行上取整。向上取整的好处:使线程数量一定满足大于等于N,即一定能满足执行N次任务的需求且浪费也最多浪费一个block的线程数量。
// 假设N是已知的
int N = 100000;// 把每个block中的thread数设为256
size_t threads_per_block = 256;// 根据N和thread数量配置Block数量
size_t number_of_blocks = (N + threads_per_block - 1) / threads_per_block;
//传入参数N
some_kernel<<>>(N);
2、网格小于工作量
请思考一下包含 1000 个元素的数组和包含 250 个线程的网格。此网格中的每个线程将需使用 4 次。如要实现此操作,一种常用方法便是在核函数中使用跨网格循环——grid-stride-loop。
在跨网格循环中,每个线程将在网格内使用 threadIdx + blockIdx * blockDim 计算自身唯一的索引,执行相应运算后,然后在自身索引的基础上跨一个总线程数大小的步长stride,并重复此操作,直至超出数组范围。
例如,对于包含 500 个元素的数组 a 和包含 250 个线程的网格,网格中索引为 20 的线程将执行如下操作:
- 对
a[20]执行相应运算; - 将线程索引增加 250,使网格的大小达到 270
- 对
a[270]执行相应运算; - 将线程索引增加 250,使网格的大小达到 520
- 由于 520 现已超出数组范围,因此线程将停止工作。
计算网格中的总线程数,即每次跨一步的大小stride = gridDim.x * blockDim.x
__global void kernel(int *a, int N)
{int indexWithinTheGrid = threadIdx.x + blockIdx.x * blockDim.x;int gridStride = gridDim.x * blockDim.x; // grid 的一个跨步for (int i = indexWithinTheGrid; i < N; i += gridStride) {// 对 a[i] 的操作;}
}
三、GPU 2D-to-2D 矩阵乘法
最简便版,最易于理解版
#include __global__ void matrixMulGPU(int *a, int *b, int *c, int N, int M, int K) {int val = 0;int ix = blockIdx.x * blockDim.x + threadIdx.x;int iy = blockIdx.y * blockDim.y + threadIdx.y;int idx = iy * M + ix;if (ix < M && iy < N) {for ( int i = 0; i < K; i ++ )val += a[iy * K + i] + b[i * M + ix]; // 这个地方的a和b里面的索引也容易错c[idx] = val;}
}void matrixMulCPU(int *a, int *b, int *c, int N, int M, int K)
{for (int i = 0; i < N; i ++ ) {for (int j = 0; j < M; j ++ ) {int &t = c[i * M + j];for (int k = 0; k < K; k ++ ) {t += a[i * K + k];}for (int k = 0; k < K; k ++ ) {t += b[k * M + j];}}}
}int main() {//随便设置int N = 88;int M = 16;int K = 32;int *a, *b, *c_cpu, *c_gpu;int size_a = N * K * sizeof (int); //N * Kint size_b = M * K * sizeof (int); // M * Kint size = N * M * sizeof (int); // N * M// 分配内存cudaMallocManaged ((void**)&a, size_a); //矩阵a的大小N * KcudaMallocManaged ((void**)&b, size_b);cudaMallocManaged ((void**)&c_cpu, size);cudaMallocManaged ((void**)&c_gpu, size);// cpu端初始化数组// 对 a 数组for (int i = 0; i < N; i ++ ) {for (int j = 0; j < K; j ++ ) {a[i * K + j] = rand() % 1024;}}// 对 b 数组for (int i = 0; i < K; i ++ ) {for (int j = 0; j < M; j ++ ) {b[i * M + j] = rand() % 1024;}}dim3 threads_per_block (32, 32, 1); //传参的时候要对应好!M 对应着 nx,N 对应着 ny。dim3 number_of_blocks ((M / threads_per_block.x) + 1, (N / threads_per_block.y) + 1, 1);matrixMulGPU <<< number_of_blocks, threads_per_block >>> (a, b, c_gpu, N, M, K); // 执行核函数cudaDeviceSynchronize(); // 同步matrixMulCPU(a, b, c_cpu, N, M, K); // 执行 CPU 版本的矩阵乘法// 比较 CPU 和 GPU 两种方法的计算结果是否一致bool error = false;for( int row = 0; row < N && !error; ++row ) {for( int col = 0; col < M && !error; ++col )if (c_cpu[row * M + col] != c_gpu[row * M + col]) {printf("FOUND ERROR at c[%d][%d]\n", row, col);error = true;break;}}if (!error)printf("Success!\n");// 释放内存cudaFree(a); cudaFree(b);cudaFree( c_cpu ); cudaFree( c_gpu );
}
最容易糊涂的就是nx和M对应,ny和N对应
