Python Xpath和 lxml库的使用
创始人
2025-05-31 20:18:34
0次
一、Xpath表达式:
XPath(全称:XML Path Language)即 XML 路径语言,它是一门在 XML 文档中查找信息的语言,最初被用来搜寻 XML 文档,同时它也适用于搜索 HTML 文档。因此,在爬虫过程中可以使用 XPath 来提取相应的数据。
Xpath节点:有父、子、同代、先辈、后代节点
java Java编程思想 2011 www.baidu.com说明:
title name year address 都是 book 的子节点 book 是 title name year address 父节点 title name year address 属于同代节点 title 元素的先辈节点是 book shop shop 的后代节点是 book title name year address
二、Xpath基本语法
1) 基本语法
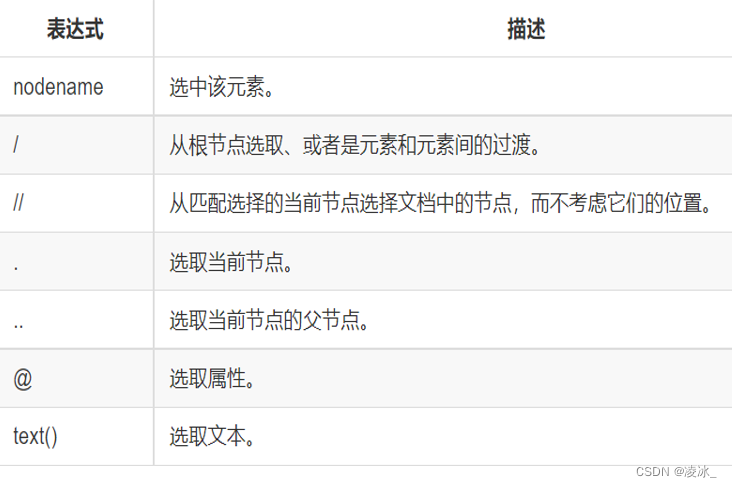
2) xpath通配符
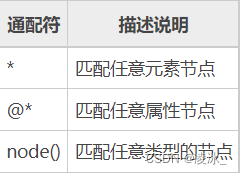
| xpath('/div/*') | 选取div下的所有子节点 |
| xpath('/div[@*]') | 选取所有带属性的div节点 |
3) 多路径匹配
xpath表达式1 | xpath表达式2 | xpath表达式3
| xpath('//div|//table') | 选取所有的div和table节点 |
4)功能函数
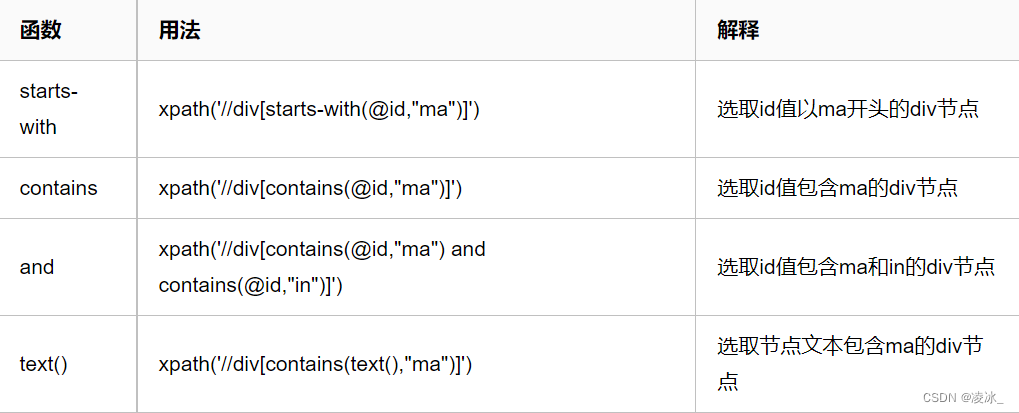
三、lxml库
lxml 是 Python 的第三方解析库,完全使用 Python 语言编写,它对 Xpath 表达式提供了良好的支持,因此能够了高效地解析 HTML/XML 文档。本节讲解如何通过 lxml 库解析 HTML 文档。
3.1 安装lxml库
pip3 install lxml
3.2 lxml使用流程
1) 导入模块
from lxml import etree
2)创建解析对象
parse_html = etree.HTML(html)
3) 调用xpath表达式
r_list = parse_html.xpath('xpath表达式')
4) lxml库数据提取
print(r_list)
四、实战案例
- 豆瓣书店
#豆瓣书店
import requests
from lxml import etreeif __name__ == '__main__':url='https://market.douban.com/book/?utm_campaign=book_nav_freyr&utm_source=douban&utm_medium=pc_web'headers_={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"}res=requests.get(url,headers_)# print(res.text)html=etree.HTML(res.text)#获取所有的lilis=html.xpath('.//li[@class="book-item"]')#循环for li in lis:#获取li下的图片img=li.xpath('.//div[@class="panel-img"]/img/@src')[0]# print(img)# 获取li下的标题title = li.xpath('.//div[@class="panel-detail"]/div/h3/text()')[0]print(img, title)
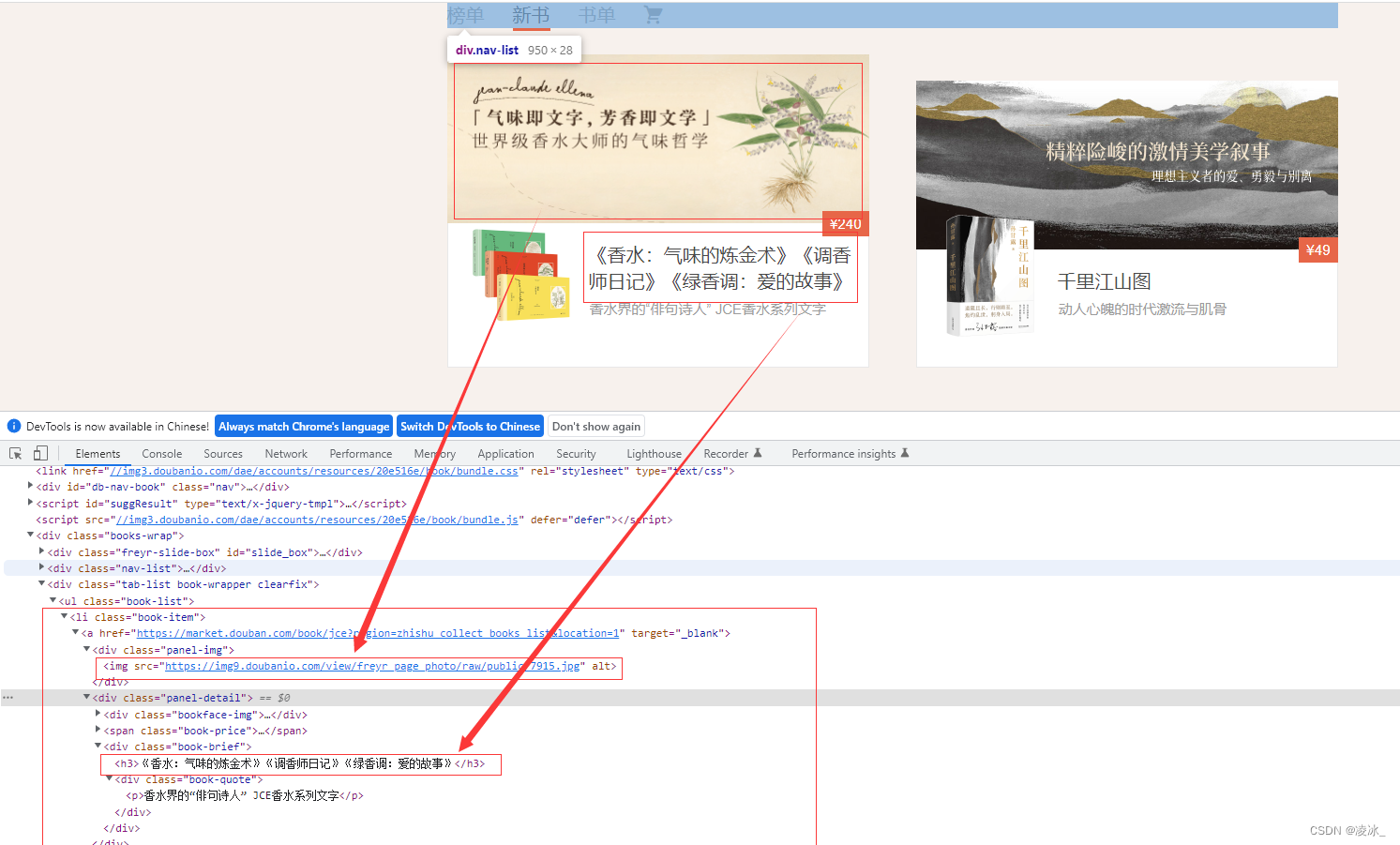
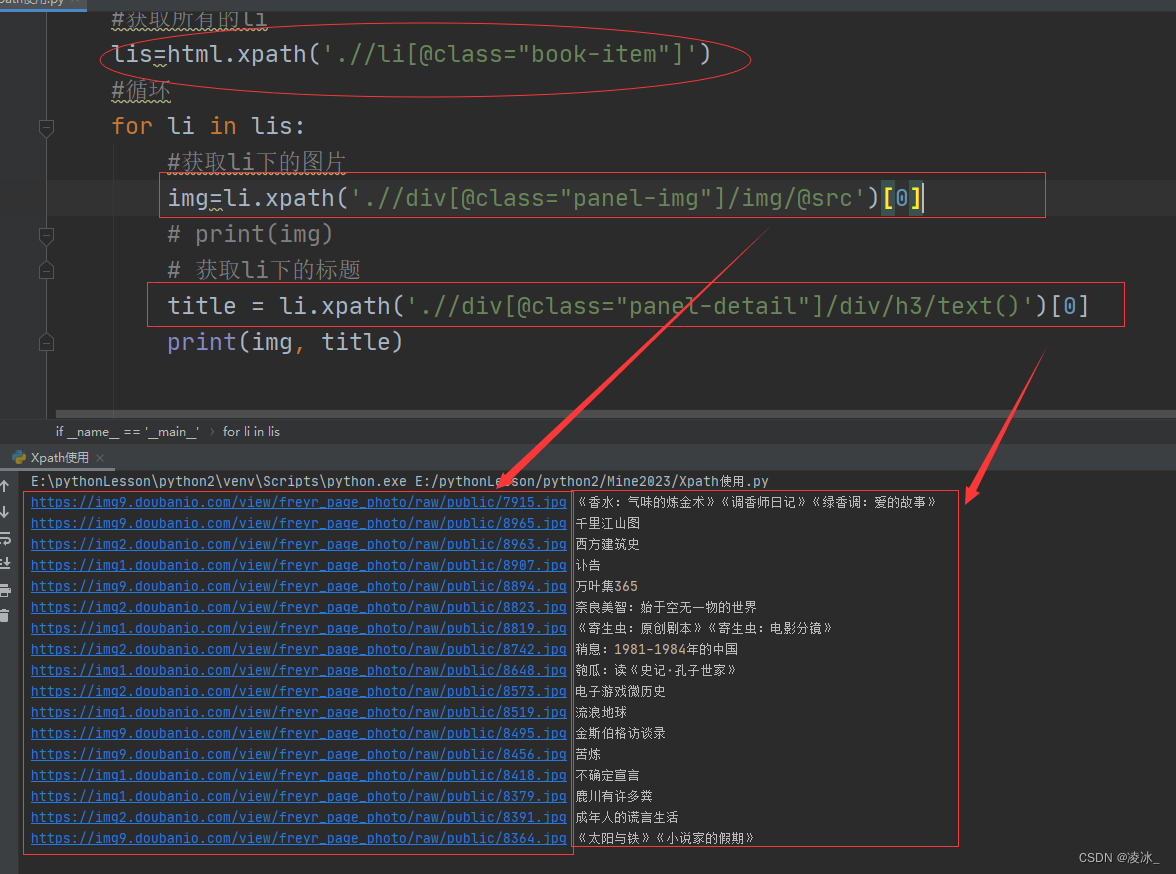
相关内容
热门资讯
linux入门---制作进度条
了解缓冲区 我们首先来看看下面的操作: 我们首先创建了一个文件并在这个文件里面添加了...
C++ 机房预约系统(六):学...
8、 学生模块 8.1 学生子菜单、登录和注销 实现步骤: 在Student.cpp的...
JAVA多线程知识整理
Java多线程基础 线程的创建和启动 继承Thread类来创建并启动 自定义Thread类的子类&#...
【洛谷 P1090】[NOIP...
[NOIP2004 提高组] 合并果子 / [USACO06NOV] Fence Repair G ...
国民技术LPUART介绍
低功耗通用异步接收器(LPUART) 简介 低功耗通用异步收发器...
城乡供水一体化平台-助力乡村振...
城乡供水一体化管理系统建设方案 城乡供水一体化管理系统是运用云计算、大数据等信息化手段...
程序的循环结构和random库...
第三个参数就是步长 引入文件时记得指明字符格式,否则读入不了 ...
中国版ChatGPT在哪些方面...
目录 一、中国巨大的市场需求 二、中国企业加速创新 三、中国的人工智能发展 四、企业愿景的推进 五、...
报名开启 | 共赴一场 Flu...
2023 年 1 月 25 日,Flutter Forward 大会在肯尼亚首都内罗毕...
汇编00-MASM 和 Vis...
Qt源码解析 索引 汇编逆向--- MASM 和 Visual Studio入门 前提知识ÿ...
【简陋Web应用3】实现人脸比...
文章目录🍉 前情提要🌷 效果演示🥝 实现过程1. u...
前缀和与对数器与二分法
1. 前缀和 假设有一个数组,我们想大量频繁的去访问L到R这个区间的和,...
windows安装JDK步骤
一、 下载JDK安装包 下载地址:https://www.oracle.com/jav...
分治法实现合并排序(归并排序)...
🎊【数据结构与算法】专题正在持续更新中,各种数据结构的创建原理与运用✨...
在linux上安装配置node...
目录前言1,关于nodejs2,配置环境变量3,总结 前言...
Linux学习之端口、网络协议...
端口:设备与外界通讯交流的出口 网络协议: 网络协议是指计算机通信网...
Linux内核进程管理并发同步...
并发同步并发 是指在某一时间段内能够处理多个任务的能力,而 并行 是指同一时间能够处理...
opencv学习-HOG LO...
目录1. HOG(Histogram of Oriented Gradients,方向梯度直方图)1...
EEG微状态的功能意义
导读大脑的瞬时全局功能状态反映在其电场结构上。聚类分析方法一致地提取了四种头表面脑电场结构ÿ...
【Unity 手写PBR】Bu...
写在前面 前期积累: GAMES101作业7提高-实现微表面模型你需要了解的知识 【技...