随机梯度下降_以及代码实现_mini-batchGD_调整学习率---人工智能工作笔记0028

然后我们首先来看一下上一节说了,批量梯度下降处理,可以看到上面的公式
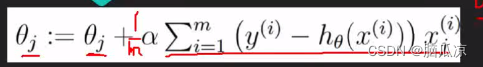
这里的thetaj: 就是下一个theta要求的,然后它 = thetaj + 阿尔法 注意阿尔法是 学习率
也就是之前我们说的,一维数据的时候 theta t+1 = theta - g .h 这里的h就是学习率,
也就是这里的阿尔法一个意思,然后后面的![]()
这个部分是学习率.

批量梯度下降,其实就是,每一个theta的获取,我们都带入m个样本数据,不是一样,我们,具体说是m行n列对吧,然后,以前我们是1维的,带入的就是1个数据了,为什么要用批量梯度下降呢,因为,虽然速度慢了,计算量大了,但是计算结果准确了对吧.
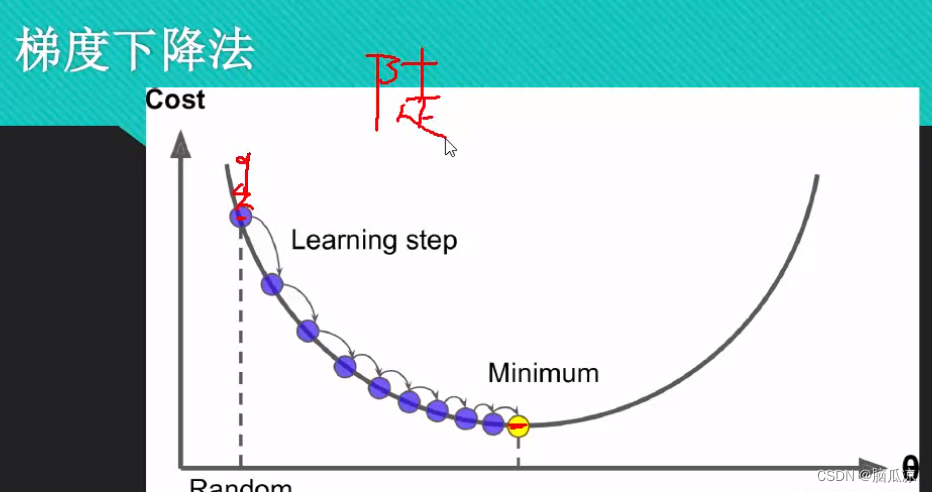
再通俗的说一下就是,如果我要下山,那么我怎么样,下山最快呢?当然不是直接下山,而是,找到一条,最快的路对吧,怎么找到最快的路,就是要看遍,所有的下山路,以后,然后才能找到,就相当于我们这里的批量梯度下降对吧...都看过一遍,就能找到最准的参数了.
那么如何进行,最快的找到,最快的下山的路呢,也就是,最快的找到 求得多维数据下的最优解...
那么这里就说道,随机梯度下降了.
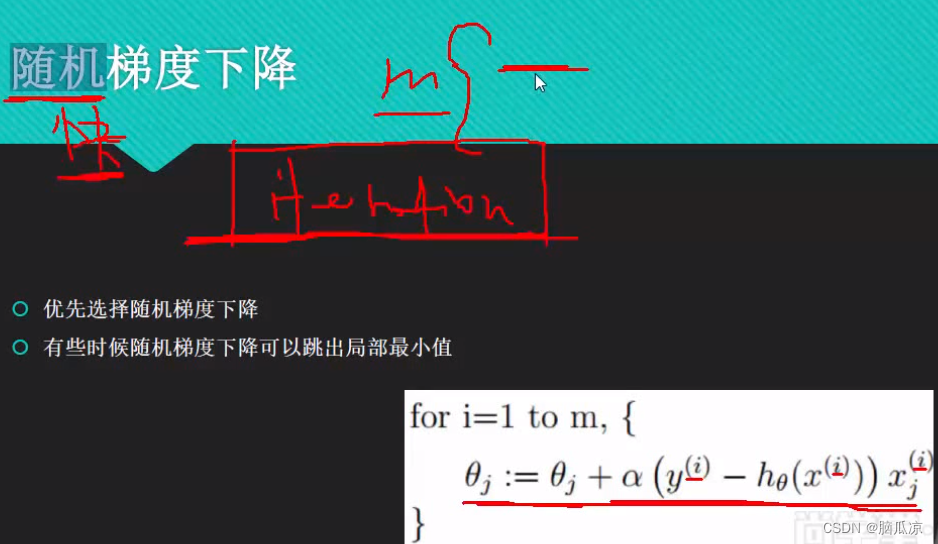
然后我们来看一下随机梯度下降,可以看到,这里,随机梯度下降其实就是,我们为了找到最快下山的路,我们有n个走法,那么我不管,走那一条路,我随便选一条,也就是在m个样本中,随机选择一个样本,然后就进行走,那么...因为是随机,选择一组样本就走,所以,走出来有可能是向下山走的,甚至有可能是上山走的路对吧...所以说,这个随机梯度下降,不好说...走的对不对,但是可以通过,提高走的次数.
迭代次数越多那么越准对吧,其实就是,考虑的,下山的路,观察的下山的路的个数越多,越能从中选择
比较快的下山路对吧.
那么到底是下山之前考虑久一点好呢,也就是使用批量梯度下降多带入样本数据呢,还是一次带入一个样本,随机梯度下降这样好呢,实际上不好说.
然后我们再来看,这里,如果我们用一次性带入大量样本来进行梯度下降的话,那么,相当于
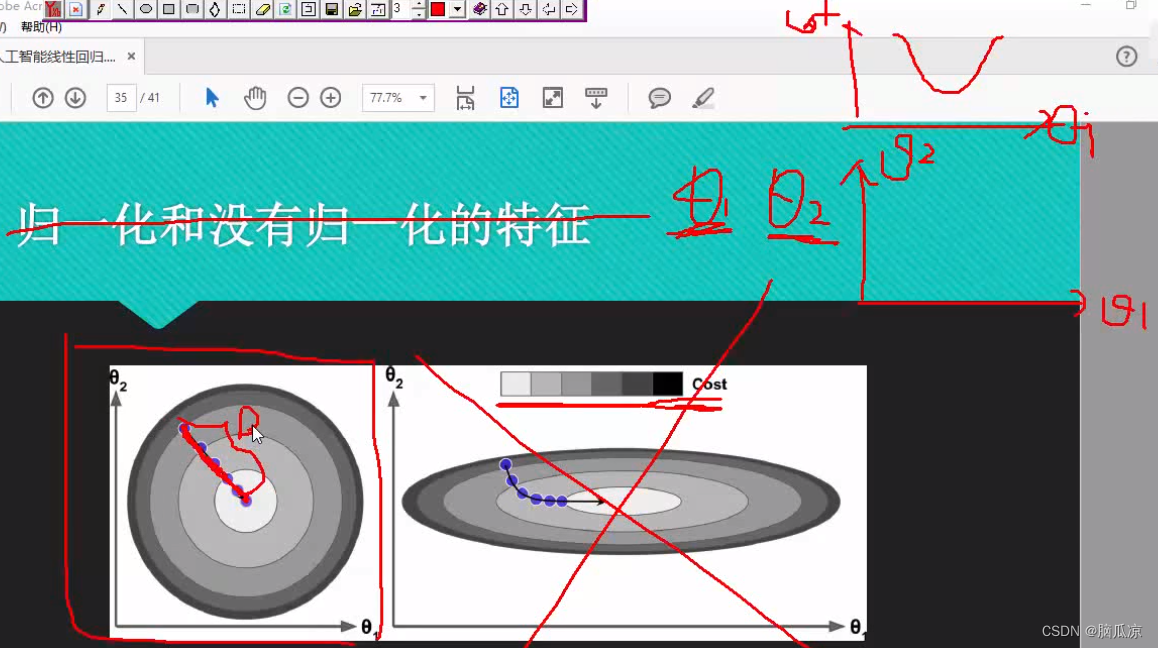
可以看到左侧,因为这个时候我们考虑了,theta1,theta2两个维度,我们这里就画成了,左侧这样的
图像,相当于,一个theta1 theta2,然后,这个theta1,theta2对应的斜率,也就是损失函数的值,cost函数的值,如果越深,说明cost越大,误差越大,然后越小误差越小,这样我们就可以画出一个圆,这样我们就相当于画出了,一个具有theta2,theta1两个维度的,加上cost损失值,3个参数的一个图了.
相当于从上方往下看,看起来是个圆,可以看到如果我们使用,一次性带入很多m样本的话,那么
每次都能找到最优的那个解,这样看上去,所有的最优解联系起来,就是一条直线,相当于以最快速度
下山了对吧.这个就是批量梯度下降.
然后如果,我们使用随机梯度下降的话.
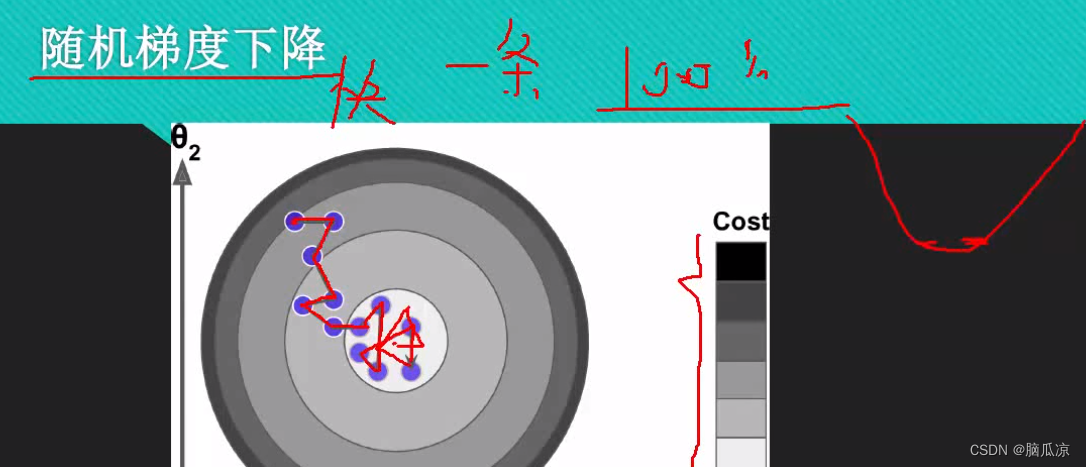
随机梯度下降因为每一次都选择m个样本中的,一个样本数据,随机选择一个样本数据进行带入,计算,所以,这个时候就可能,走的时候,算出来的cost损失,不是最优的,所以如果比喻成下山的话,可以看到,cost表示颜色越深,随机误差越大,那么...有可能就不会一次性,能找到最优解,就会出现,走弯路的情况,还有可能发现,走了上山路对吧,然后又反过来了...但是总之,随着迭代次数越来越多,结果会
越来越接近最优解,也就是说损失越来越小,这样就够了对吧,因为我们说,我们做机器学习,并不是要求一定要,百分之100的准,只要在,正态分布的相对底部,满足我们的需求就可以了.
而随机梯度特点就是快,我们想用最快的速度得到,能接受的结果对吧,这个就是为什么要用随机梯度下降的原因.
然后我们再来看一下,既然随机梯度下降,也不行有问题对吧,走的每一步都有可能不对,而且有可能方向走反了,那么怎么弄呢?
那就是我不随机m个样本中的一条对吧,我随机m个样本中的,一部分对吧,这样,如果,我随机的那一个样本可能是,异常数据,或者是离群数据的话,还能被,其他样本纠正过来.
这样也是一个折中的办法,就是随机m个样本中的一部分数据,而不是仅仅随机一个样本数据对吧.
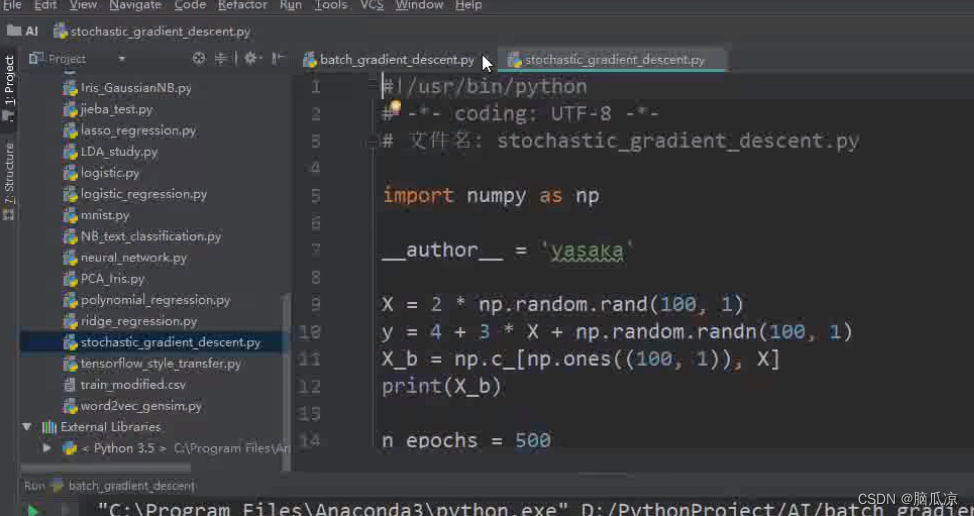
然后我们用代码来看一下随机梯度下降怎么做的,首先对应的
import
x=
y= 以及定义x_b,这些基本的准备x,y数据,以及我们先不说了,上一节也说了,这里要知道x_b,我们是2维的数据对吧,有x0,x1可以理解是
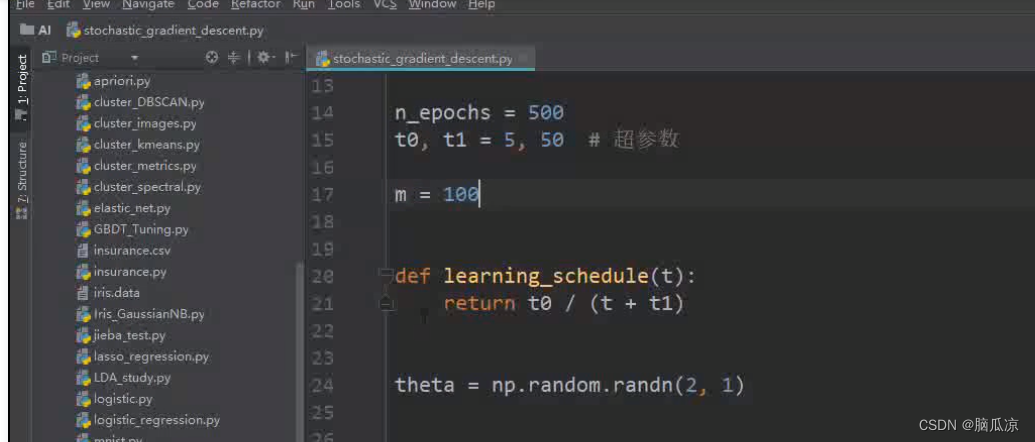
然后这里m=100,是有100个样本数据,然后这里的 定义了一个 learning_schedule(t)这个
函数,我们就先不看
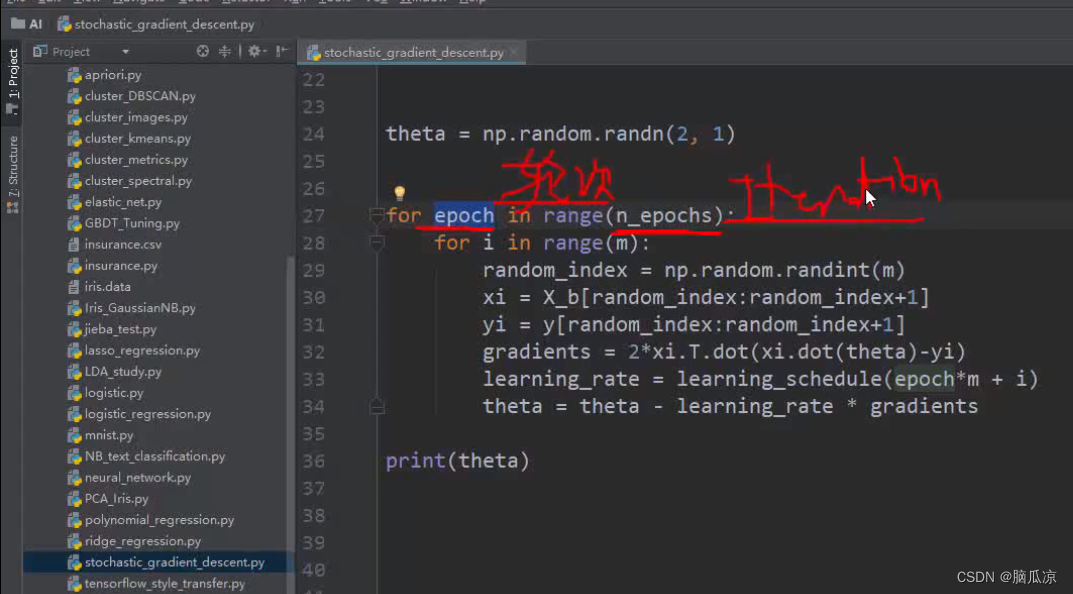
然后这里的theta = np.random.randn(2,1) 生成两个theta值,符合标准正态分布,其实就是两行1列的值对吧,符合标准正态分布的值.
然后下面这里for epoch in range(n_epochs) 这里的epoch是轮次的意思,我们可以理解成一次迭代,
这里n_epochs是500对吧
然后这里我们先不看,for epoch for i这两行,我们直接看
random_index = np.random.randint(m) m是100,这个就是从100中随机拿出来一个整数,然后,拿出来一个0到99的数,做为index对吧
然后x_b[random_index:random_index+1] 这个random_index:random_index+1 就是从x_b矩阵中,获取 random_index到random_index+1 为下标的这两行数据,然后yi也是对吧
上一篇:线性代数 --- 投影与最小二乘 下(多元方程组的最小二乘解与向量在多维子空间上的投影)
下一篇:Elasticsearch:保护你的 Elasticsearch 实例 - 如何使用带有内置证书的 Docker 镜像