SparkSQL-SparkOneHive
创始人
2025-05-29 17:00:05
0次
部署
连接Hive操作
小试牛刀:Hive版本的WordCount
从MySQL中读取数据存储到hive中
部署
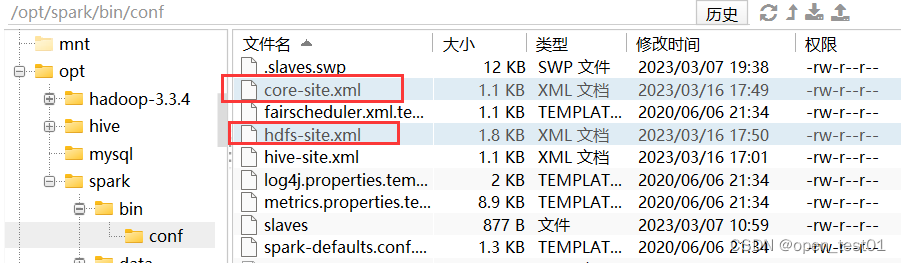
1、Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下

2、把 Mysql 的驱动 copy 到 jars/目录下
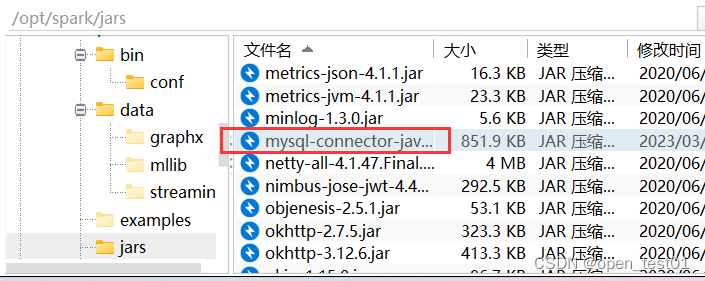
3、 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
导入依赖
org.apache.spark spark-hive_2.12 3.0.0
org.apache.hive hive-exec 1.2.1
mysql mysql-connector-java 5.1.27
将 hive-site.xml 文件拷贝到项目的 resources 目录中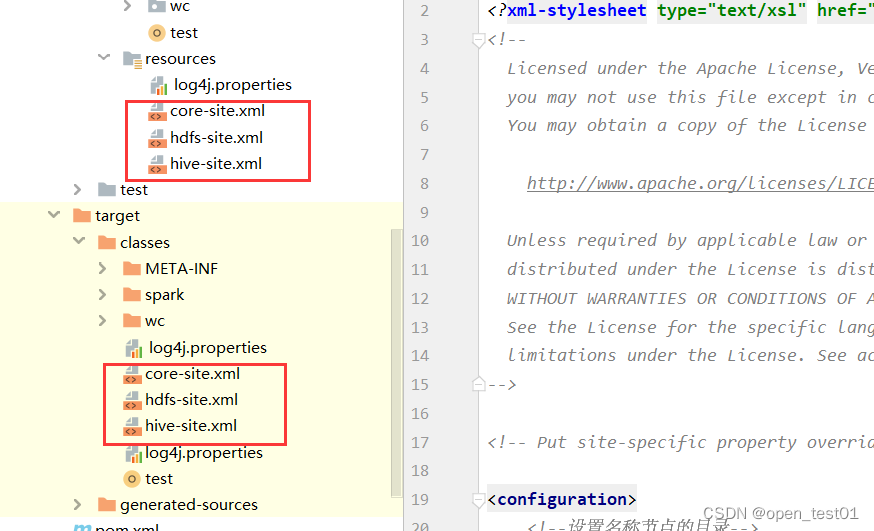
虚拟机中后台启动hive
hiveserver2 &nohup hive --service metastore &连接Hive操作
在操作hive时,需要对哪个库的表进行操作则需要写 -> 数据库名.表名 不然都会默认使用default数据库
spark.sql("select * from ee.user")def main(args: Array[String]): Unit = {//创建Session对象val spark = SparkSession.builder() //构建器.appName("sparkSQL") //序名称程.master("local[*]") //执行方式:本地.enableHiveSupport() //支持hive相关操作.getOrCreate() //创建对象spark.sql("select * from ee.user")spark.close()}小试牛刀:Hive版本的WordCount
注意: 当开启了enableHiveSupport()机制之后可能会导致在本地磁盘的文件会有突然读取不到的清空。原因是hive默认会从HDFS上面获取数据文件
想访问本地磁盘时的解决方法:需在本地磁盘路径前添加file:///
spark.read.text("file:///datas\\a.txt")def main(args: Array[String]): Unit = {//创建Session对象val spark = SparkSession.builder() //构建器.appName("sparkSQL") //序名称程.master("local[*]") //执行方式:本地.enableHiveSupport() //支持hive相关操作.getOrCreate() //创建对象val df: DataFrame = spark.read.text("file:///D:\\spark.test\\datas\\a.txt") //载入数据df.createTempView("wc") //创建表spark.sql("""|select tmp.word,count(tmp.word) from(|select explode(split(value," ")) word from wc|)tmp|group by tmp.word|order by count desc|""".stripMargin).show()spark.close()}从MySQL中读取数据存储到hive中
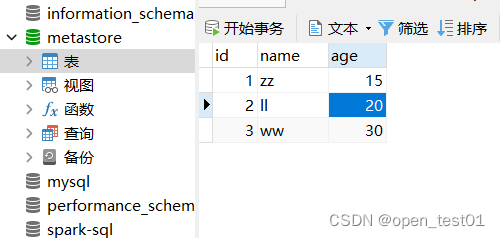
准备MySQL数据库user表
向Hive创建表时 操作hive权限问题 因为是创建到HDFS上所以要提供root用户权限
System.setProperty("HADOOP_USER_NAME","root")def main(args: Array[String]): Unit = {//创建Session对象val spark = SparkSession.builder() //构建器.appName("sparkSQL") //序名称程.master("local[*]") //执行方式:本地.enableHiveSupport() //支持hive相关操作.getOrCreate() //创建对象//从MySQL中读取数据存储到hive中 //添加操作HDFS的用户名System.setProperty("HADOOP_USER_NAME","root")//创建info表spark.sql( //需指定数据库不然会创建到默认数据库下"""|create table ee.test(|id int,|name string,|age int|)|""".stripMargin)//jdbc读取mysqlval pro = new Properties()pro.put("user","root") //指定用户名pro.put("password","p@ssw0rd") //指定密码//jdbc("路径","表名","Properties对象")val df = spark.read.jdbc("jdbc:mysql://master:3306/spark-sql","user",pro)df.write.insertInto("ee.test")spark.sql("select * from ee.test").show()spark.close()}相关内容
热门资讯
linux入门---制作进度条
了解缓冲区 我们首先来看看下面的操作: 我们首先创建了一个文件并在这个文件里面添加了...
C++ 机房预约系统(六):学...
8、 学生模块 8.1 学生子菜单、登录和注销 实现步骤: 在Student.cpp的...
JAVA多线程知识整理
Java多线程基础 线程的创建和启动 继承Thread类来创建并启动 自定义Thread类的子类&#...
【洛谷 P1090】[NOIP...
[NOIP2004 提高组] 合并果子 / [USACO06NOV] Fence Repair G ...
国民技术LPUART介绍
低功耗通用异步接收器(LPUART) 简介 低功耗通用异步收发器...
城乡供水一体化平台-助力乡村振...
城乡供水一体化管理系统建设方案 城乡供水一体化管理系统是运用云计算、大数据等信息化手段...
程序的循环结构和random库...
第三个参数就是步长 引入文件时记得指明字符格式,否则读入不了 ...
中国版ChatGPT在哪些方面...
目录 一、中国巨大的市场需求 二、中国企业加速创新 三、中国的人工智能发展 四、企业愿景的推进 五、...
报名开启 | 共赴一场 Flu...
2023 年 1 月 25 日,Flutter Forward 大会在肯尼亚首都内罗毕...
汇编00-MASM 和 Vis...
Qt源码解析 索引 汇编逆向--- MASM 和 Visual Studio入门 前提知识ÿ...
【简陋Web应用3】实现人脸比...
文章目录🍉 前情提要🌷 效果演示🥝 实现过程1. u...
前缀和与对数器与二分法
1. 前缀和 假设有一个数组,我们想大量频繁的去访问L到R这个区间的和,...
windows安装JDK步骤
一、 下载JDK安装包 下载地址:https://www.oracle.com/jav...
分治法实现合并排序(归并排序)...
🎊【数据结构与算法】专题正在持续更新中,各种数据结构的创建原理与运用✨...
在linux上安装配置node...
目录前言1,关于nodejs2,配置环境变量3,总结 前言...
Linux学习之端口、网络协议...
端口:设备与外界通讯交流的出口 网络协议: 网络协议是指计算机通信网...
Linux内核进程管理并发同步...
并发同步并发 是指在某一时间段内能够处理多个任务的能力,而 并行 是指同一时间能够处理...
opencv学习-HOG LO...
目录1. HOG(Histogram of Oriented Gradients,方向梯度直方图)1...
EEG微状态的功能意义
导读大脑的瞬时全局功能状态反映在其电场结构上。聚类分析方法一致地提取了四种头表面脑电场结构ÿ...
【Unity 手写PBR】Bu...
写在前面 前期积累: GAMES101作业7提高-实现微表面模型你需要了解的知识 【技...